[Python] Featuretools로 고객데이터 분석하기
요즘 학회에서 기업 컨택을 통해 서비스 데이터를 다루는 프로젝트를 진행 중인데, 고객 세그먼트와 RFM분석에 관한 내용이 팀 내부적으로 논의되고 있어 관련한 방법론을 찾아보았다. 그러던 도중 'Featuretools'라는 라이브러리를 알게되었고, 추가적으로 'Datetime' 라이브러리를 활용해 RFM 및 코호트 분석을 실습해보았다. 오늘은 이 고객데이터 분석 실습 전 과정에 대한 내용을 다루고자 한다.
Featuretools
Featuretools는 파이썬에서 자동으로 피처 엔지니어링을 수행해주는 라이브러리로, 특히 복잡한 데이터 관계에서 새로운 피처를 생성하는 데 유용하다. RFM 분석에서 Featuretools를 활용하면 다양한 형태의 피처를 자동으로 생성하여 더 정교한 분석을 할 수 있다.
<Featuretools의 주요 특징>
1. 자동 피처 엔지니어링
여러 테이블 간의 관계를 정의하고 자동으로 피처를 생성한다. 특히 고객-구매 데이터와 같은 관계형 데이터를 다룰 때 효과적이다.
- EntitySet : 여러 개의 엔티티(데이터프레임)를 관리하는 객체. 이를 통해 데이터 간의 관계를 정의하고, 피처 엔지니어링을 위한 기초를 마련한다.
- EntitySet()을 사용해 새로운 EntitySet을 생성.
- add_dataframe(): EntitySet에 데이터프레임을 추가.
- normalize_dataframe(): 데이터프레임을 정규화하여 새로운 엔티티를 생성하고, 자동으로 관계를 설정.
- Relationships : 서로 다른 엔티티 간의 부모-자식 관계를 정의한다.
- add_relationship(): 두 엔티티 간의 관계를 정의하고 EntitySet에 추가.
2. Aggregation 및 Transformation
날짜 및 시간 기준의 다양한 집계와 변환을 쉽게 적용하여 복잡한 피처를 생성할 수 있다. 예를 들어 RFM 분석에서는 고객의 마지막 구매일, 구매 빈도, 총 구매 금액 등을 자동으로 계산해준다.
변환 프리미티브 (Transformation Primitives)
데이터의 개별 행에 대해 변환 작업을 수행한다.
- Math Operations
- Absolute : 절대값 반환.
- AddNumeric: 두 숫자를 더함.
- SubtractNumeric: 두 숫자를 뺌.
- MultiplyNumeric: 두 숫자를 곱합.
- DivideNumeric: 두 숫자를 나눔.
- Datetime Transformations
- Year: 날짜에서 연도를 추출.
- Month: 날짜에서 월을 추출.
- Day: 날짜에서 일을 추출.
- Hour: 시간에서 시각을 추출.
- DayOfWeek: 날짜에서 요일을 추출.
- IsWeekend: 날짜가 주말인지 여부를 반환.
- Text Transformations
- Upper: 텍스트를 모두 대문자로 변환.
- Lower: 텍스트를 모두 소문자로 변환.
- Len: 텍스트의 길이를 반환.
- Other Transformations
- IsNull: 값이 null인지 확인.
- Not: 논리 NOT 연산을 수행.
- Percentile: 값의 백분위를 반환.
집계 프리미티브 (Aggregation Primitives)
집계 프리미티브는 그룹화된 데이터에서 요약 통계를 생성합니다.
- Statistical Aggregations
- Sum: 합계를 계산.
- Mean: 평균을 계산.
- Min: 최소값을 반환.
- Max: 최대값을 반환.
- Std: 표준 편차를 계산.
- Count: 개수를 계산.
- Median: 중위수를 계산.
- Mode: 최빈값을 반환.
- Time-based Aggregations
- TimeSinceLast: 마지막 발생 이후 경과 시간을 계산.
- TimeSinceFirst: 첫 발생 이후 경과 시간을 계산.
- Custom Aggregations:
- NumUnique: 고유 값의 수를 계산.
- NumTrue: 참(True) 값의 수를 계산.
- Any: 하나 이상의 참(True) 값이 있는지 확인.
- All: 모든 값이 참(True)인지 확인.
3. Deep Feature Synthesis (DFS)
데이터의 계층적 구조를 분석하고 자동으로 피처를 생성해 주는 기능으로, 이를 통해 복잡한 피처를 생성할 수 있다.
- ft.dfs(): 자동 피처 생성 함수로, 다양한 설정을 통해 피처를 생성.
- 주요 하이퍼파라미터
- entityset: DFS를 적용할 엔티티셋.
- target_dataframe_name: 피처를 생성할 타겟 엔티티.
- max_depth: 생성할 피처의 복잡성(깊이)를 설정.
- agg_primitives: 집계 프리미티브(예: sum, mean 등)를 지정.
- trans_primitives: 변환 프리미티브(예: day, month, divide 등)를 지정.
그렇다면 'Online_retail_II' 샘플 데이터셋을 활용해 실습을 진행해보자.
# 필요 라이브러리 호출
import featuretools as ft
import pandas as pd
df = pd.read_excel('Online_retail_II.xlsx')
현재 df의 유니크한 인덱스가 없는 상황이므로 인덱스를 먼저 생성하고 Entityset을 추가할 예정이다.
# 인덱스 설정
df['transaction_id'] =df.index
# Entityset 생성
es = ft.EntitySet()
# 엔티티 추가
es = es.add_dataframe(dataframe_name='transactions', dataframe=df, index='transaction_id', time_index='InvoiceDate')
# 기존에 있는 df에서 고객 엔티티를 추가하기 위해 새롭게 es에 담기
es = es.normalize_dataframe(base_dataframe_name='transactions',new_dataframe_name='customers', index='Customer ID')
# 변환, 집계 프리미티브 추가
feature_matrix, feature_defs = ft.dfs(
entityset= es
,target_dataframe_name = 'customers'
,agg_primitives = ["sum",'mean','count','median']
,trans_primitives = ['Year', 'Month','day']
,max_depth=2)
엔티티 생성 후 변환, 집계 프리미티브를 추가해 새로운 변수들을 생성하는 과정을 거쳤다. 이후 feature_matrix를 확인하면 아래와 같다.

그렇다면 생성된 여러 변수들을 바탕으로 상관분석을 진행해 최종 피처를 선정해보도록 하자.
# 상관계수, 분산 기반 상관분석 진행
from sklearn.feature_selection import VarianceThreshold
# y의 값을 하나를 지정해서 유의미한 피처들 찾기
target_variable = 'COUNT(transactions)'
corr_matrix =feature_matrix.corr()
target_corr = corr_matrix[target_variable]
# 임계값 설정하여 피처 선정
selected_by_corr =target_corr[abs(target_corr)>0.1].index
selector = VarianceThreshold(threshold=0.1)
selected_by_variacne=feature_matrix.columns[selector.fit(feature_matrix).get_support()]
상관계수와 분산에 의해 출력한 변수들이다. 이 중 공통적으로 출력된 피처들만 선정했고(common_features), k-means 군집화를 통한 고객 세분화를 진행해보자.
X = feature_matrix[common_features]
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
# K-means 진행
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 엘보우 시각화를 통해 적정 k값 찾기
sse = []
k_range = range(2,11)
for k in k_range:
kmeans=KMeans(n_clusters= k, random_state=111)
kmeans.fit(X_scaled)
sse.append(kmeans.inertia_)
plt.figure(figsize=(10,6))
plt.plot(k_range, sse, marker='o')
plt.title('Elbow Method for Opitmal K')
plt.xlabel('Number of clusters')
plt.xlabel('sse')
# 실루엣을 통해 최적의 K를 찾기
silhouette_scores = []
for k in k_range:
kmeans=KMeans(n_clusters= k, random_state=111)
labels = kmeans.fit_predict(X_scaled)
silhouette_avg = silhouette_score(X_scaled, labels)
silhouette_scores.append(silhouette_avg)
plt.figure(figsize=(10,6))
plt.plot(k_range, silhouette_scores, marker='o')
plt.title('silhouette_scores for Opitmal K')
plt.xlabel('Number of clusters')
plt.xlabel('silhouette_scores')
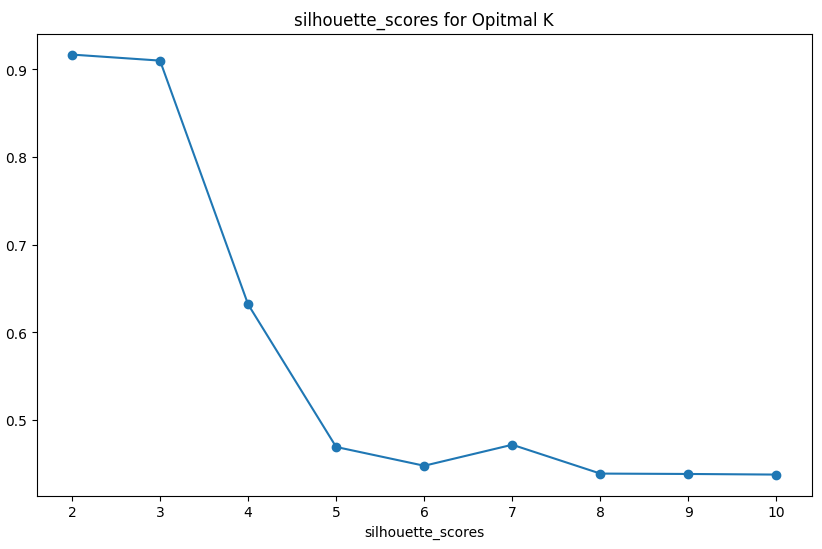
그렇다며 이제 앞서 잠깐 언급한 Datetime 라이브러리를 활용해 RFM 분석을 진행해보자. 분석을 진행하기 전에 RFM은 무엇일까?
RFM은 Recency(최근성), Frequency(빈도), Monetary(금액)의 약자로, 고객의 구매 행동을 바탕으로 세 가지 주요 요소를 분석해 고객 세그멘테이션을 수행하는 기법으로, 마케팅, CRM에서 많이 사용되며, 고객을 유형별로 나누고 각각의 특성에 맞는 맞춤형 전략을 세울 수 있다.
- Recency : 특정 일과 가장 최근에 주문한 일의 차이
- Frequency : 주문 빈도
- Monetary : 주문 금액
import datetime as dt
df
# R,F,M 계산
today_date = dt.datetime(2010,12,10)
rfm = df.groupby('Customer ID').agg({'InvoiceDate': lambda x: (today_date - x.max()).days,
'Invoice': lambda x: x.nunique(),
'Price': lambda x: x.sum()})
rfm.columns = ['recency', 'frequency', 'monetary']
# rfm['monetary'] = rfm[rfm['monetary'] > 0]
rfm = rfm.reset_index()
rfm.head()
이후에는 R, F, M 각각 수치에 따라 분석가의 주관적인 해석을 곁들여 RFM Score를 만들 수 있다. Customer 별 충성도를 수치적으로 파악하기 위한 과정이라 볼 수 있다.
def get_rfm_scores(dataframe) -> pd.core.frame.DataFrame:
df_ = dataframe.copy()
df_["recency_score"] = pd.qcut(df_["recency"], 5, labels=[5, 4, 3, 2, 1])
df_["frequency_score"] = pd.qcut(
df_["frequency"].rank(method="first"), 5, labels=[1, 2, 3, 4, 5]
)
df_["monetary_score"] = pd.qcut(df_["monetary"], 5, labels=[1, 2, 3, 4, 5])
df_["RFM_SCORE"] = df_["recency_score"].astype(str) + df_["frequency_score"].astype(
str
)
return df_
rfm = get_rfm_scores(rfm)
전처리한 스코어를 바탕으로 태깅작업도 가능하다.
seg_map = {r'[1-2][1-2]': 'hibernating',
r'[1-2][3-4]': 'at_Risk',
r'[1-2]5': 'cant_loose',
r'3[1-2]': 'about_to_sleep',
r'33': 'need_attention',
r'[3-4][4-5]': 'loyal_customers',
r'41': 'promising',
r'51': 'new_customers',
r'[4-5][2-3]': 'potential_loyalists',
r'5[4-5]': 'champions'}
rfm['segment'] = rfm['RFM_SCORE'].replace(seg_map, regex = True)
rfm.head()
트리맵 시각화를 도와주는 squarify라이브러리를 활용해 세그먼트를 확인하면,
segments = rfm["segment"].value_counts().sort_values(ascending=False)
fig = plt.gcf()
ax = fig.add_subplot()
fig.set_size_inches(16, 10)
squarify.plot(
sizes=segments,
label=[label for label in seg_map.values()],
color=[
"#AFB6B5",
"#F0819A",
"#926717",
"#F0F081",
"#81D5F0",
"#C78BE5",
"#748E80",
"#FAAF3A",
"#7B8FE4",
"#86E8C0",
],
pad=False,
bar_kwargs={"alpha": 1},
text_kwargs={"fontsize": 15},
)
plt.title("Customer Segmentation Map", fontsize=20)
plt.xlabel("Frequency", fontsize=18)
plt.ylabel("Recency", fontsize=18)
plt.show()
2차원 형태로 F, R 값만 확인할 수 있지만 트리맵 형태로 시각화도 가능하다.
그러면 마지막으로 간단한 코호트 분석을 통해 유저 리텐션을 확인해보자.
from operator import attrgetter
import matplotlib.colors as mcolors
def CohortAnalysis(dataframe):
# 입력된 데이터프레임을 복사하여 사용
data = dataframe.copy()
# 중복된 Customer ID, Invoice, InvoiceDate 열을 제거한 후 데이터프레임 생성
data = data[["Customer ID", "Invoice", "InvoiceDate"]].drop_duplicates()
# 주문 월을 계산하여 order_month 열에 추가
data["order_month"] = data["InvoiceDate"].dt.to_period("M")
# 각 고객이 처음 주문한 날짜의 월을 계산하여 cohort 열에 추가
data["cohort"] = (
data.groupby("Customer ID")["InvoiceDate"].transform("min").dt.to_period("M")
)
# 코호트와 주문 월별로 고객 수를 계산
cohort_data = (
data.groupby(["cohort", "order_month"])
.agg(n_customers=("Customer ID", "nunique"))
.reset_index(drop=False)
)
# 기간 번호를 계산하여 period_number 열에 추가
cohort_data["period_number"] = (cohort_data.order_month - cohort_data.cohort).apply(
attrgetter("n")
)
# 피벗 테이블을 생성하여 코호트별 기간 번호에 따른 고객 수를 계산
cohort_pivot = cohort_data.pivot_table(
index="cohort", columns="period_number", values="n_customers"
)
# 각 코호트의 고객 수를 계산
cohort_size = cohort_pivot.iloc[:, 0]
# 유지율 매트릭스를 생성 (각 코호트별 기간 동안 남아있는 고객 비율)
retention_matrix = cohort_pivot.divide(cohort_size, axis=0)
# 유지율을 히트맵으로 시각화
with sns.axes_style("white"):
fig, ax = plt.subplots(
1, 2, figsize=(12, 8), sharey=True, gridspec_kw={"width_ratios": [1, 11]}
)
# 고객 유지율 히트맵 그리기
sns.heatmap(
retention_matrix,
mask=retention_matrix.isnull(), # 데이터가 없는 부분은 마스킹
annot=True, # 각 셀에 값 표시
cbar=False, # 컬러 바는 표시하지 않음
fmt=".0%", # 퍼센트 포맷
cmap="coolwarm", # 컬러맵 설정
ax=ax[1], # 두 번째 축에 그리기
)
ax[1].set_title("Monthly Cohorts: User Retention", fontsize=14) # 그래프 제목 설정
ax[1].set(xlabel="# of periods", ylabel="") # x축 라벨 설정, y축 라벨은 빈칸
# 첫 번째 축에 각 코호트의 고객 수를 히트맵으로 그리기 (하얀색 컬러맵 사용)
white_cmap = mcolors.ListedColormap(["white"])
sns.heatmap(
pd.DataFrame(cohort_size).rename(columns={0: "cohort_size"}), # 코호트 사이즈를 데이터프레임으로 변환
annot=True, # 각 셀에 값 표시
cbar=False, # 컬러 바는 표시하지 않음
fmt="g", # 숫자 포맷
cmap=white_cmap, # 하얀색 컬러맵 사용
ax=ax[0], # 첫 번째 축에 그리기
)
fig.tight_layout() # 레이아웃 조정
# 데이터프레임 df에 대해 CohortAnalysis 함수 실행
CohortAnalysis(df)