[LLM] Transformer - Masked Multi-Head Attention, Residual Connection
지난 글에서 트랜스포머 아키텍처의 가장 핵심인 Attention과 Self Attention에 대해 알아보았는데, 오늘은 트랜스포머 아키텍처가 지니는 특징적인 부분을 다뤄보자.
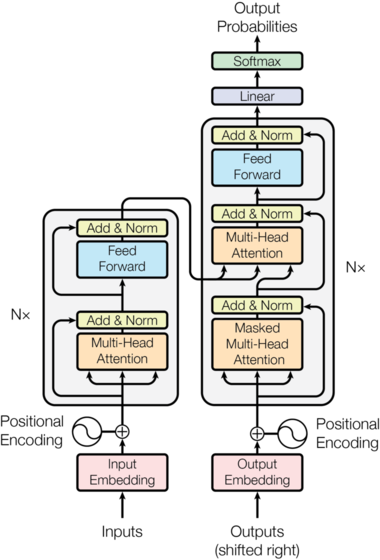
위의 트랜스포머 아키텍처 구조를 살펴보면 어텐션의 경우 인코더와 디코더 모두 'Multi-Head Attention'을 수행하고, 특히 디코더에서는 'Masked Multi-Head Attention'을 수행한다. 이 두 가지는 무엇일까.
Multi-Head Attention

트랜스포머 모델의 Multi-Attention은 위 그림처럼 head의 수만큼 Attention을 각각 병렬로 나누어 계산을 한다. 도출된 Attention Value들은 마지막에 concatenate를 통해 하나로 합쳐진다. 이렇게 하면 Attention을 한번 사용할 때와 같은 크기의 결과가 도출된다. Google research에 따르면 한 번에 계산하는 것보다 여러 개를 나누어 병렬 계산하는 Multi-head Attention 메커니즘이 성능이 더 좋다. 그 이유는 병렬 계산을 통해 각 head가 서로 정보를 상호 보완하기 때문이다.
Masked?

Masked Multi-Head Attention은 Multi-Head Attention에 '마스킹'을 추가한 것이다. 즉 무언가를 가린다는 의미인데, 마스킹은 특정 위치의 정보를 무시하도록 강제하는 역할을 한다. 이는 주로 트랜스포머 모델의 디코더에서 사용되며, 시퀀스 생성 시 미래의 정보를 참조하지 못하도록 제한한다.
트랜스포머 모델도 딥러닝 모델 중 일부이므로 인간의 뇌와 동일한 사고 구조를 지니도록 설계되는데, 인간의 뇌는 기본적으로 번역을 할 때 첫 번째 단어를 유추하고 그 다음 단어를 예측하는, 왼쪽에서부터 순서대로 번역을 진행한다. '너를 사랑해'라는 문장을 번역할 때, 'I'를 먼저 생각한 뒤, 뒤의 동사로 'love'를 이어서 생각하지, 처음부터 맨 마지막에 위치할 'you'를 떠올리지는 않는다. 하지만 트랜스포머 모델은 기존의 RNN 계열 모델과는 다르게 번역당할 문장을 한꺼번에 입력받기 때문에 'I'라는 단어를 떠올릴 때, 뒤의 'love'와 'you'까지 모두 고려해 번역하게 된다. 이는 인간이 번역할 때 사고하는 과정과 모순되기 때문에, 트랜스포머 모델은 디코더에서 Masked Multi-Head Attention을 수행한다.
정리하자면, 디코더에서 현재 시점 이후의 정보를 볼 수 없도록 함으로써 'I love you'라는 문장을 생성할 경우, 'I'를 생성할 때 'love'나 'you'를 참조하지 못하도록 한다. 이는 시퀀스 생성의 순차성을 보장한다.
이는 어텐션 계산 시, 마스킹을 적용하여 미래 시점의 Key와 Query 간 내적을 통해 도출된 유사도를 0에 가까운 값으로 설정해, Value가 어텐션 가중치의 영향을 받지 않도록 구현할 수 있다.
Residual Connection

위 이미지를 보면 트랜스포머 모델에서 임베딩과 포지셔널 인코딩을 거치고 input 값이 어텐션 수행을 하는 것이 아닌, 우회하는 화살표 하나가 보인다. 이는 바로 Add&Norm의 'Add'에 해당하는 부분이다. Norm은 정규화에 해당하므로 많이 들어봤을 개념이지만 이 Add는 왜 하는걸까.


보통 인코더와 디코더에 input을 입력하면 여러 layer를 거쳐 output이 도출되고 이 output과 실제 true값 사이에는 loss가 존재한다. 예를 들어 output값이 4, true값이 5라면, loss는 1이 되는 것이다. 이렇게 손실이 발생할 경우 우리는 output에서 input으로 가중치를 업데이트하는 역전파를 수행하는데, 이때 layer가 많을 경우 점점 input 단으로 갈수록 기울기가 0에 수렴하는 현상이 발생한다. 이를 기울기 소실 문제(Vanishing Gradient)라고 한다. 이 문제가 발생하면 가중치가 0에 수렴해, 모델이 필요 정보를 제대로 학습하지 못한다. 이를 해결하기 위한 방법이 'Residual Connection'이다. 위의 왼쪽 이미지처럼 Residual Connection을 통해 output 즉, f(x) 값에 다시 input 즉, x값을 더해줌으로써 기울기 소실 문제를 방지할 수 있다.