
짜리몽땅 매거진
[SQL] Google Analytics 웹사이트 접속 및 사용 분석 본문
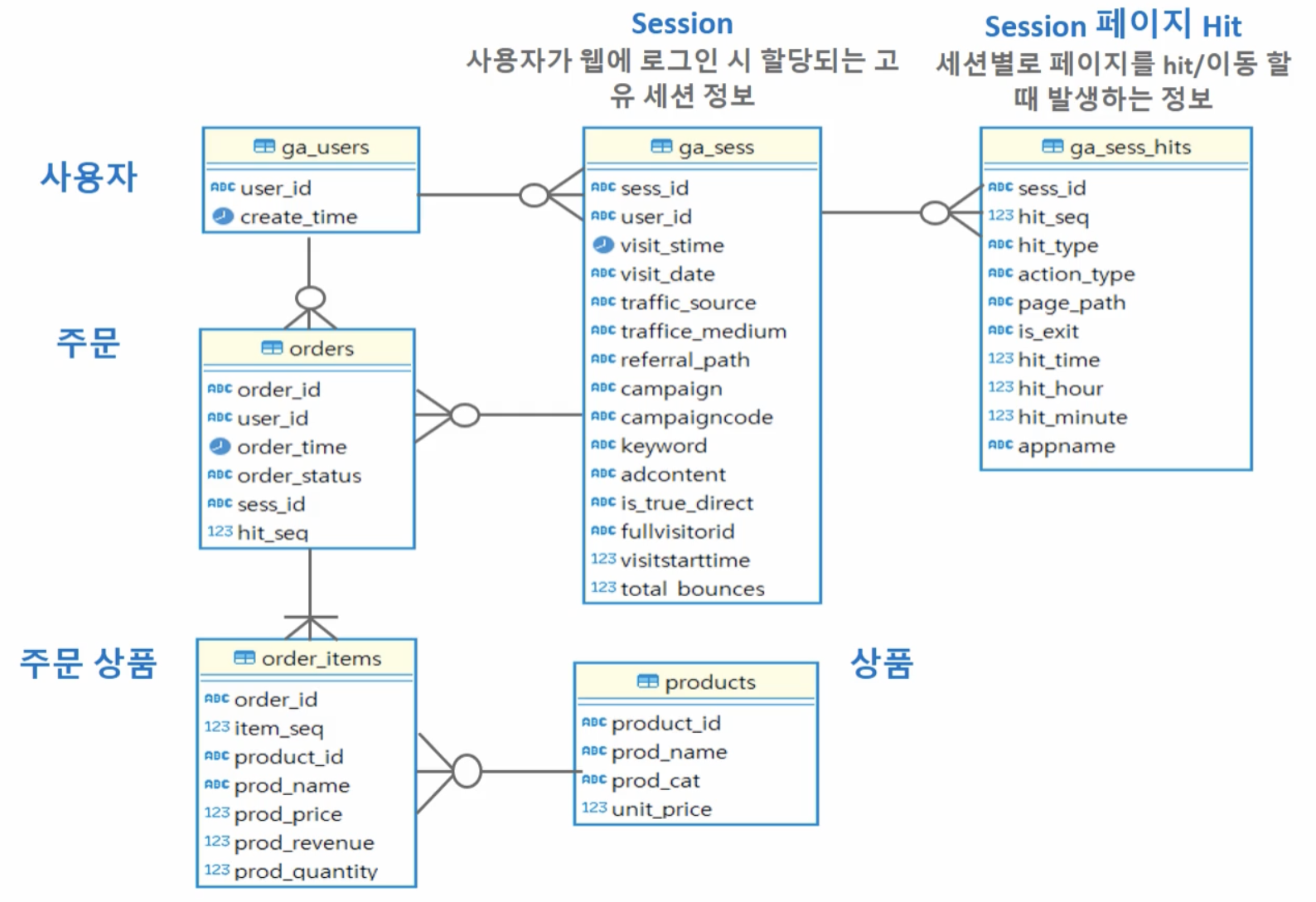
0. 데이터 구조
- 주의깊게 볼만한 테이블 : ga_sess , ga_sess_hits

1. 일별 세션 건수, 일별 방문 사용자, 사용자별 평균 세션
with temp_01 as
(
select to_char(date_trunc('day', visit_stime), 'yyyy-mm-dd') as d_day
-- ga_sess 테이블에는 sess_id로 unique하므로 count(sess_id)와 동일
, count(distinct sess_id) as daily_sess_cnt
, count(sess_id) as daily_sess_cnt_again
, count(distinct user_id) as daily_user_cnt
from ga.ga_sess group by to_char(date_trunc('day', visit_stime), 'yyyy-mm-dd')
)
select *
, 1.0*daily_sess_cnt/daily_user_cnt as avg_user_sessions
-- 아래와 같이 정수와 정수를 나눌 때 postgresql은 정수로 형변환 함. 1.0을 곱해주거나 명시적으로 float type선언
from temp_01;
일별 세션 건수 : 고유키인 sess_id를 카운트 (distinct로 출력해도 고유키이기 때문에 출력값은 동일)
일별 방문 사용자 : user_id를 distinct로 카운트, 하루에 동일한 유저가 여러번 접속할 수 있기 때문
사용자별 평균 세션 : 일별 세션 건수에서 일별 방문 사용자를 나눈다.
—> 이때 주의할 점이 postgresql은 정수끼리 나눌 때 정수값을 출력하므로, 1.0을 곱하거나 float type을 선언해 정확한 실수 값을 출력할 필요가 있다.
<시각화 결과>

- 주말에 세션 수가 줄어드는 현상 = 주말에 접속 수가 적다는 뜻(파란색)
- 방문 유저는 주말에 줄어들긴 하지만 전체적인 기간에 있어 유지되는 수준(주황색)
2. DAU, WAU, MAU
DAU : 하루 동안 접속한 순수 유저 수
WAU : 일주일(=7일간) 동안 접속한 순수 유저 수
MAU : 한 달(=30일간) 동안 접속한 순수 유저 수
<다양한 코드>
-- 일별 방문한 고객 수(DAU)
select date_trunc('day', visit_stime)::date as d_day, count(distinct user_id) as user_cnt
from ga.ga_sess
where visit_stime between to_date('2016-10-25', 'yyyy-mm-dd') and to_timestamp('2016-10-31 23:59:59', 'yyyy-mm-dd hh24:mi:ss')
group by date_trunc('day', visit_stime)::date;
-- 주별 방문한 고객수(WAU)
select date_trunc('week', visit_stime)::date as week_d기y, count(distinct user_id) as user_cnt
from ga.ga_sess
where visit_stime between to_date('2016-10-24', 'yyyy-mm-dd') and to_timestamp('2016-10-31 23:59:59', 'yyyy-mm-dd hh24:mi:ss')
group by date_trunc('week', visit_stime)::date order by 1;
-- 월별 방문한 고객수(MAU)
select date_trunc('month', visit_stime)::date as month_day, count(distinct user_id) as user_cnt
from ga.ga_sess
where visit_stime between to_date('2016-10-24', 'yyyy-mm-dd') and to_timestamp('2016-10-31 23:59:59', 'yyyy-mm-dd hh24:mi:ss')
group by date_trunc('month', visit_stime)::date;
- 단순히 해당 일자만을 준으로 DAU, WAU, MAU를 출력함. 다른 날짜를 기준으로 보고 싶다면 코드의 날짜를 모두 수정해야하는 번거로움.
-- interval로 전일 7일 구하기
select to_date('20161101', 'yyyymmdd') - interval '7 days';
-- 현재 일을 기준으로 전 7일의 WAU 구하기
select :current_date, count(distinct user_id) as wau
from ga_sess
where visit_stime >= (:current_date - interval '7 days') and visit_stime < :current_date;
-- 현재 일을 기준으로 전일의 DAU 구하기
select :current_date, count(distinct user_id) as dau
from ga_sess
where visit_stime >= (:current_date - interval '1 days') and visit_stime < :current_date;
- interval : 날짜 및 시간 값에 대한 연산을 수행할 때 사용되는 함수. interval을 사용하면 일, 시간, 분, 초 등의 값을 날짜 및 시간 값에 더하거나 빼는 등의 연산을 쉽게 수행할 수 있다.
- date/time value: 연산 대상이 되는 날짜 및 시간 값
- value: 더하거나 빼고자 하는 값
- interval unit: 더하거나 빼고자 하는 값의 단위 (예: YEAR, MONTH, DAY, HOUR, MINUTE, SECOND)
- date/time value + interval + value + interval unit
- :current date : ‘:’를 통해 변수로 설정, 출력 시 아래 창에서 날짜를 한 번만 바꿔주면 됨.

-- 날짜별로 DAU, WAU, MAU 값을 가지는 테이블 생성.
create table if not exists daily_acquisitions
(d_day date,
dau integer,
wau integer,
mau integer
);
--daily_acquisitions 테이블에 지정된 current_date별 DAU, WAU, MAU을 입력
insert into daily_acquisitions
select
:current_date,
-- scalar subquery는 select 절에 사용가능하면 단 한건, 한 컬럼만 추출되어야 함.
(select count(distinct user_id) as dau
from ga_sess
where visit_stime >= (:current_date - interval '1 days') and visit_stime < :current_date
),
(select count(distinct user_id) as wau
from ga_sess
where visit_stime >= (:current_date - interval '7 days') and visit_stime < :current_date
),
(select count(distinct user_id) as mau
from ga_sess
where visit_stime >= (:current_date - interval '30 days') and visit_stime < :current_date
)
;
- 스칼라 서브쿼리 : select 절에 사용하는 서브쿼리로, 반드시 하나의 행만이 결과로 출력되어야 함.
사용위치 명칭
| select 절 | 스칼라 서브쿼리 |
| from 절 | 인라인 뷰 |
| where 절 | 중첩 서브쿼리 or 서브쿼리 |
-- 과거 일자별로 DAU 생성하는 임시 테이블 생성
create table daily_dau
as
with
temp_00 as (
select generate_series('2016-08-02'::date , '2016-11-01'::date, '1 day'::interval)::date as current_date
)
select b.current_date, count(distinct user_id) as dau
from ga_sess a
cross join temp_00 b
where visit_stime >= (b.current_date - interval '1 days') and visit_stime < b.current_date
group by b.current_date
;
-- 과거 일자별로 WAU 생성하는 임시 테이블 생성
drop table if exists daily_wau;
create table daily_wau
as
with
temp_00 as (
select generate_series('2016-08-02'::date , '2016-11-01'::date, '1 day'::interval)::date as current_date
)
select b.current_date, count(distinct user_id) as wau
from ga_sess a
cross join temp_00 b
where visit_stime >= (b.current_date - interval '7 days') and visit_stime < b.current_date
group by b.current_date;
-- 과거 일자별로 MAU 생성하는 임시 테이블 생성
drop table if exists daily_mau;
create table daily_mau
as
with
temp_00 as (
select generate_series('2016-08-02'::date , '2016-11-01'::date, '1 day'::interval)::date as current_date
)
select b.current_date, count(distinct user_id) as mau
from ga_sess a
cross join temp_00 b
where visit_stime >= (b.current_date - interval '30 days') and visit_stime < b.current_date
group by b.current_date;
-- DAU, WAU, MAU 임시테이블을 일자별로 조인하여 daily_acquisitions 테이블 생성.
drop table if exists daily_acquisitions;
create table daily_acquisitions
as
select a.current_date, a.dau, b.wau, c.mau
from daily_dau a
join daily_wau b on a.current_date = b.current_date
join daily_mau c on a.current_date = c.current_date
;
- generate series
Function Argument Type Return Type Description
| generate_series(start, stop) | int or bigint | (same as argument type) | 1의 단위로 증감 |
| generate_series(start, stop, step) | int or bigint | (same as argument type) | step에서 설정한 단위로 증감 |
| generate_series(start, stop, step interval) | timestamp or timestamp with time zone | (same as argument type) | step에서 설정한 단위로 증감 |
- cross join
- CROSS JOIN은 첫 번째 테이블의 각 행을 두 번째 테이블의 각 행과 결합하여 두 테이블의 곱을 생성하는 JOIN 작업 유형입니다. 테이블 JOIN에는 조건이 필요하지 않습니다. CROSS JOIN의 결과 집합에는 JOIN되는 두 테이블의 행 수를 곱한 것과 동일한 행 수가 있습니다.
위의 코드에서는 cross join으로 나올 수 있는 모든 경우의 행을 출력한 뒤 where 조건으로 해당 기간에만 해당하는 날짜만 뽑아낸다. group by를 통해 날짜별 DAU, WAU, MAU를 보여주고 마지막 join을 통해 세가지 지표를 한꺼번에 출력.
만약 CROSS JOIN을 사용하지 않고 JOIN을 한다면, 일치하는 날짜에 해당하는 세션만을 고려하고, 다른 날짜에 대한 정보는 무시될 것임. 즉, CROSS JOIN을 사용하는 것은 모든 날짜에 대해 각각의 세션과의 관계를 확인하기 위한 것.
3. 고척도(Stickiness)
/************************************
DAU와 MAU의 비율. 고착도(stickiness) 월간 사용자들중 얼마나 많은 사용자가 주기적으로 방문하는가? 재방문 지표로 서비스의 활성화 지표 제공.
*************************************/
--DAU와 MAU의 비율
with
temp_dau as (
select :current_date as curr_date, count(distinct user_id) as dau
from ga.ga_sess
where visit_stime >= (:current_date - interval '1 days') and visit_stime < :current_date
),
temp_mau as (
select :current_date as curr_date, count(distinct user_id) as mau
from ga.ga_sess
where visit_stime >= (:current_date - interval '30 days') and visit_stime < :current_date
)
select a.current_day, a.dau, b.mau, round(100.0 * a.dau/b.mau, 2) as stickieness
from temp_dau a
join temp_mau b on a.curr_date = b.curr_date
;
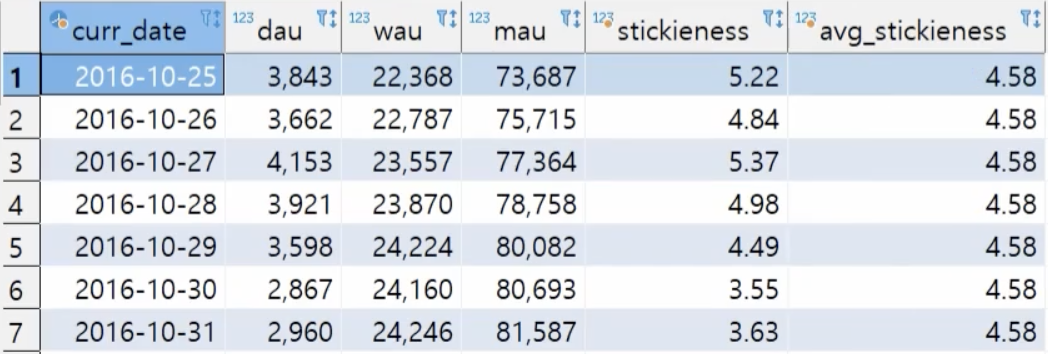
-- 일주일간 stickiess, 평균 stickness
select *, round(100.0 * dau/mau, 2) as stickieness
, round(avg(100.0 * dau/mau) over(), 2) as avg_stickieness
from ga.daily_acquisitions
where curr_date between to_date('2016-10-25', 'yyyy-mm-dd') and to_date('2016-10-31', 'yyyy-mm-dd')
4. 사용자별 월별 세션 접속 횟수의 구간별 분포 집계
/************************************
사용자별 월별 세션 접속 횟수 구간별 분포 집계
*************************************/
-- user 생성일자가 해당 월의 마지막 일에서 3일전인 user 추출.
select user_id, create_time, (date_trunc('month', create_time) + interval '1 month' - interval '1 day')::date
from ga.ga_users
where create_time <= (date_trunc('month', create_time) + interval '1 month' - interval '1 day')::date - 2;
-- 사용자별 월별 세션접속 횟수, 월말 3일 이전 생성된 사용자 제외
select a.user_id, date_trunc('month', visit_stime)::date as month
-- 사용자별 접속 건수. 고유 접속 건수가 아니므로 count(distinct user_id)를 적용하지 않음.
, count(*) as monthly_user_cnt
from ga_sess a
join ga_users b on a.user_id = b.user_id
where b.create_time <= (date_trunc('month', b.create_time) + interval '1 month' - interval '1 day')::date - 2
group by a.user_id, date_trunc('month', visit_stime)::date;
-- 사용자별 월별 세션 접속 횟수 구간별 집계, 월말 3일 이전 생성된 사용자 제외
with temp_01 as (
select a.user_id, date_trunc('month', visit_stime)::date as month, count(*) as monthly_user_cnt
from ga.ga_sess a
join ga_users b on a.user_id = b.user_id
where b.create_time <= (date_trunc('month', b.create_time) + interval '1 month' - interval '1 day')::date - 2
group by a.user_id, date_trunc('month', visit_stime)::date
- 유저 생성일자가 해당 월의 마지막 일에서 3일 전인 유저만 추출하고 싶음. but, postgresql은 last_day()함수가 없음. 때문에 해당 일자가 속한 달의 첫번째 날짜 가령 10월 5일이면 10월 1일에 1달을 더하고 거기에 1일을 뺌. 즉 10월 5일 → 10월 1일 → 11월 1일 → 10월 31일 → 10월 29일 순으로 계산함.
- where b.create_time <= (date_trunc('month', b.create_time) + interval '1 month' - interval '1 day')::date - 2
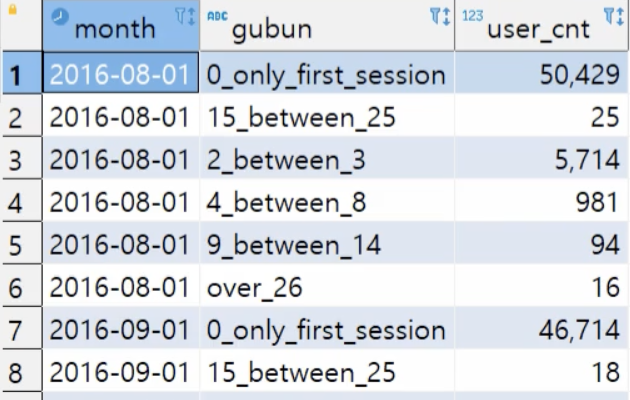
select month
,case when monthly_user_cnt = 1 then '0_only_first_session'
when monthly_user_cnt between 2 and 3 then '2_between_3'
when monthly_user_cnt between 4 and 8 then '4_between_8'
when monthly_user_cnt between 9 and 14 then '9_between_14'
when monthly_user_cnt between 15 and 25 then '15_between_25'
when monthly_user_cnt >= 26 then 'over_26' end as gubun
, count(*) as user_cnt
from temp_01
group by month,
case when monthly_user_cnt = 1 then '0_only_first_session'
when monthly_user_cnt between 2 and 3 then '2_between_3'
when monthly_user_cnt between 4 and 8 then '4_between_8'
when monthly_user_cnt between 9 and 14 then '9_between_14'
when monthly_user_cnt between 15 and 25 then '15_between_25'
when monthly_user_cnt >= 26 then 'over_26' end
order by 1, 2;
-- gubun 별로 pivot 하여 추출
with temp_01 as (
select a.user_id, date_trunc('month', visit_stime)::date as month, count(*) as monthly_user_cnt
from ga.ga_sess a
join ga.ga_users b
on a.user_id = b.user_id
where b.create_time <= (date_trunc('month', b.create_time) + interval '1 month' - interval '1 day')::date - 2
group by a.user_id, date_trunc('month', visit_stime)::date
),
temp_02 as (
select month
,case when monthly_user_cnt = 1 then '0_only_first_session'
when monthly_user_cnt between 2 and 3 then '2_between_3'
when monthly_user_cnt between 4 and 8 then '4_between_8'
when monthly_user_cnt between 9 and 14 then '9_between_14'
when monthly_user_cnt between 15 and 25 then '15_between_25'
when monthly_user_cnt >= 26 then 'over_26' end as gubun
, count(*) as user_cnt
from temp_01
group by month,
case when monthly_user_cnt = 1 then '0_only_first_session'
when monthly_user_cnt between 2 and 3 then '2_between_3'
when monthly_user_cnt between 4 and 8 then '4_between_8'
when monthly_user_cnt between 9 and 14 then '9_between_14'
when monthly_user_cnt between 15 and 25 then '15_between_25'
when monthly_user_cnt >= 26 then 'over_26' end
)
select month,
sum(case when gubun='0_only_first_session' then user_cnt else 0 end) as "0_only_first_session"
,sum(case when gubun='2_between_3' then user_cnt else 0 end) as "2_between_3"
,sum(case when gubun='4_between_8' then user_cnt else 0 end) as "4_between_8"
,sum(case when gubun='9_between_14' then user_cnt else 0 end) as "9_between_14"
,sum(case when gubun='15_between_25' then user_cnt else 0 end) as "15_between_25"
,sum(case when gubun='over_26' then user_cnt else 0 end) as "over_26"
from temp_02
group by month order by 1;

- pivot 함수
https://im-first-rate.tistory.com/130
위 링크에서도 볼 수 있듯이 강의의 코드와 실제 pivot 함수 구문은 차이가 있다. 강의 코드는 pivot함수를 사용했다고 보긴 어렵고 그냥 select와 집계 함수를 이용해 행열을 새롭게 지정했다고 볼 수 있다. (pivot함수로 행열을 빠르게 전환하는 코드도 학습하면 어떨까 하는 마음에 남겨둡니다!)
5. 첫 세션 접속 후 두번째 세션 접속까지 걸리는 시간 추출
-- 사용자 별로 접속 시간에 따라 session 별 순서 매김.
select user_id, row_number() over (partition by user_id order by visit_stime) as session_rnum
, visit_stime
, count(*) over (partition by user_id) as session_cnt
from ga_sess
order by user_id, session_rnum;
--session 별 순서가 첫번째와 두번째 인것 추출하고 사용자 별로 첫번째 세션의 접속 이후 두번째 세션의 접속 시간 차이를 가져 오기
with
temp_01 as (
select user_id, row_number() over (partition by user_id order by visit_stime) as session_rnum
, visit_stime
, count(*) over (partition by user_id) as session_cnt
from ga_sess
)
select user_id
, max(visit_stime) - min(visit_stime) as sess_time_diff
from temp_01 where session_rnum <= 2 and session_cnt > 1 -- 첫번째 두번째 세션만 가져오되 첫번째 접속만 있는 사용자를 제외하기
group by user_id;
-- 전체 평균, 최대값, 최소값, 4분위 percentile 구하기.
with
temp_01 as (
select user_id, row_number() over (partition by user_id order by visit_stime) as session_rnum
, visit_stime
-- 추후에 1개 session만 있는 사용자는 제외하기 위해 사용.
, count(*) over (partition by user_id) as session_cnt
from ga_sess
),
temp_02 as (
select user_id
-- 사용자별로 첫번째 세션, 두번째 세션만 있으므로 max(visit_stime)이 두번째 세션 접속 시간, min(visit_stime)이 첫번째 세션 접속 시간.
, max(visit_stime) - min(visit_stime) as sess_time_diff
from temp_01 where session_rnum <= 2 and session_cnt > 1
group by user_id
)
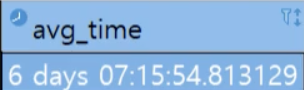
-- postgresql avg(time)은 interval이 제대로 고려되지 않음. justify_inteval()을 적용해야 함.
select justify_interval(avg(sess_time_diff)) as avg_time
, max(sess_time_diff) as max_time, min(sess_time_diff) as min_time
, percentile_disc(0.25) within group (order by sess_time_diff) as percentile_1
, percentile_disc(0.5) within group (order by sess_time_diff) as percentile_2
, percentile_disc(0.75) within group (order by sess_time_diff) as percentile_3
, percentile_disc(1.0) within group (order by sess_time_diff) as percentile_4
from temp_02
where sess_time_diff::interval > interval '0 second';
- justify_interval
- postgresql에서 제공하는 함수로 기간을 보정하여 특정 시간 단위에 맞게 정규화하는 데 사용하는 구문이다.
- SELECT JUSTIFY_INTERVAL(INTERVAL '25 hours') : 이와 같은 구문이 있다면 25시간을 1일과 1시간으로 변환하여 결과를 반환할 것
- justify_interval을 사용하지 않았을 경우와 사용했을 경우 결과 차이
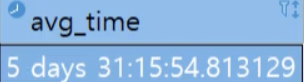
- within group
- 숫자 열을 그룹화하고 각 그룹 내에서 정렬된 값을 기반으로 집계 함수를 적용할 때 사용
- 예시 쿼리
'Data > SQL' 카테고리의 다른 글
| [SQL] 프로그래머스 코딩테스트 연습3 (1) | 2024.02.27 |
|---|---|
| [SQL] 프로그래머스 코딩테스트 연습2 (0) | 2024.02.19 |
| [SQL] 프로그래머스 코딩테스트 연습1 (1) | 2024.02.05 |
| [SQL] LEFT JOIN, RIGHT JOIN, FULL JOIN, CROSS JOIN, INNER JOIN (0) | 2023.08.21 |
| [SQL] IF, CASE, 함수 만들기 (0) | 2023.08.16 |


