
짜리몽땅 매거진
[ML] Kmeans 알고리즘 + DBSCAN 본문
Kmeans알고리즘은 머신러닝 비지도학습에 속하는 K-means 알고리즘은 쉽게 말해 데이터를 K개의 군집(Cluster)으로 묶는(Clusting) 알고리즘이다. 군집이란 쉽게 말해서 비슷한 특성을 지닌 데이터들을 모아놓은 그룹(Group)이다. 마찬가지로 군집화는 군집으로 묶는다는 의미로 해석할 수 있다.
Kmeans알고리즘은 KNN알고리즘과 구분하는 것이 중요한데, 분류와 군집화의 차이점에 대해 간단히 살펴보자.
분류
분류는 지도학습 방법에 속하여 정답이 주어졌을 때 정답을 기반으로 데이터를 나누는 방법을 의미한다. 따라서 머신러닝에서 모델을 학습시킬 때 모델이 제대로 분류하는지를 평가하기 위해 정답을 제거하고 모델이 예측한 레이블과 실제 레이블을 비교하여 모델의 성능을 판단한다.
군집화
반면, 군집화는 비지도학습 방법에 속하여 정답이 주어지지 않았을 때 주어진 데이터를 묶는 방법을 의미한다. 정해진 레이블이 없기 때문에 분류와 달리 어떤 레이블에 속할지 예측하기 보다는 이렇게 군집화 될 수 있구나 정도만 파악이 가능하며 이 정보가 필요할 경우 군집화 알고리즘을 사용한다.
그렇다면 Mall customer 샘플 데이터셋을 활용하여 Kmeans알고리즘 실습을 진행해보자.
0. 라이브러리 호출
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.cluster import KMeans
from yellowbrick.cluster import KElbowVisualizer
from sklearn.metrics import silhouette_score
from yellowbrick.cluster import SilhouetteVisualizer
군집화 결과를 확인하기 위한 라이브러리까지 함께 호출해준다.
1. 인코딩, 스케일링 작업
# 데이터 스케일링 진행
# 원핫인코딩 진행을 통해 gender 수치 변환
# drop_first 를 통해 다중공산성 문제 해결
df_sp=pd.get_dummies(df_sp, columns = ['Gender'],drop_first=True)
#스케일링 진행
mns = MinMaxScaler()
df_mns =mns.fit_transform(df_sp)
#컬럼 다시 합치기
df_mns_sp = pd.DataFrame(data =df_mns, columns =df_sp.columns)
2. Kmeans 진행
kmeans_model1 = KMeans(
init='k-means++',
n_clusters = 3,
n_init= 10,
max_iter = 200,
random_state=111)
kmeans_model1.fit(df_mns_sp)
위와 같이 적절한 파라미터 값을 입력하고 Kmeans를 진행했다면 군집화가 잘 되었는지 엘보우 차트와 실루엣 계수를 통해 확인할 수 있다.
3. Elbow Chart
Elbow_ch=KElbowVisualizer(kmeans_model1)
# 학습데이터를 넣고 fit
Elbow_ch.fit(df_mns_sp)
# 옐보우 그리기
Elbow_ch.draw()
4. Silhouette_coef
silhouette_coef= []
#실루엣계수 그래프 그리기
for i in range(2,11):
kmeans_sil = KMeans(n_clusters=i, **kmeans_model1)
kmeans_sil.fit(df_mns_sp)
score = silhouette_score(df_mns_sp, kmeans_sil.labels_)
silhouette_coef.append(score)
plt.plot(range(2,11),silhouette_coef )
plt.xticks(range(2,11))
plt.show()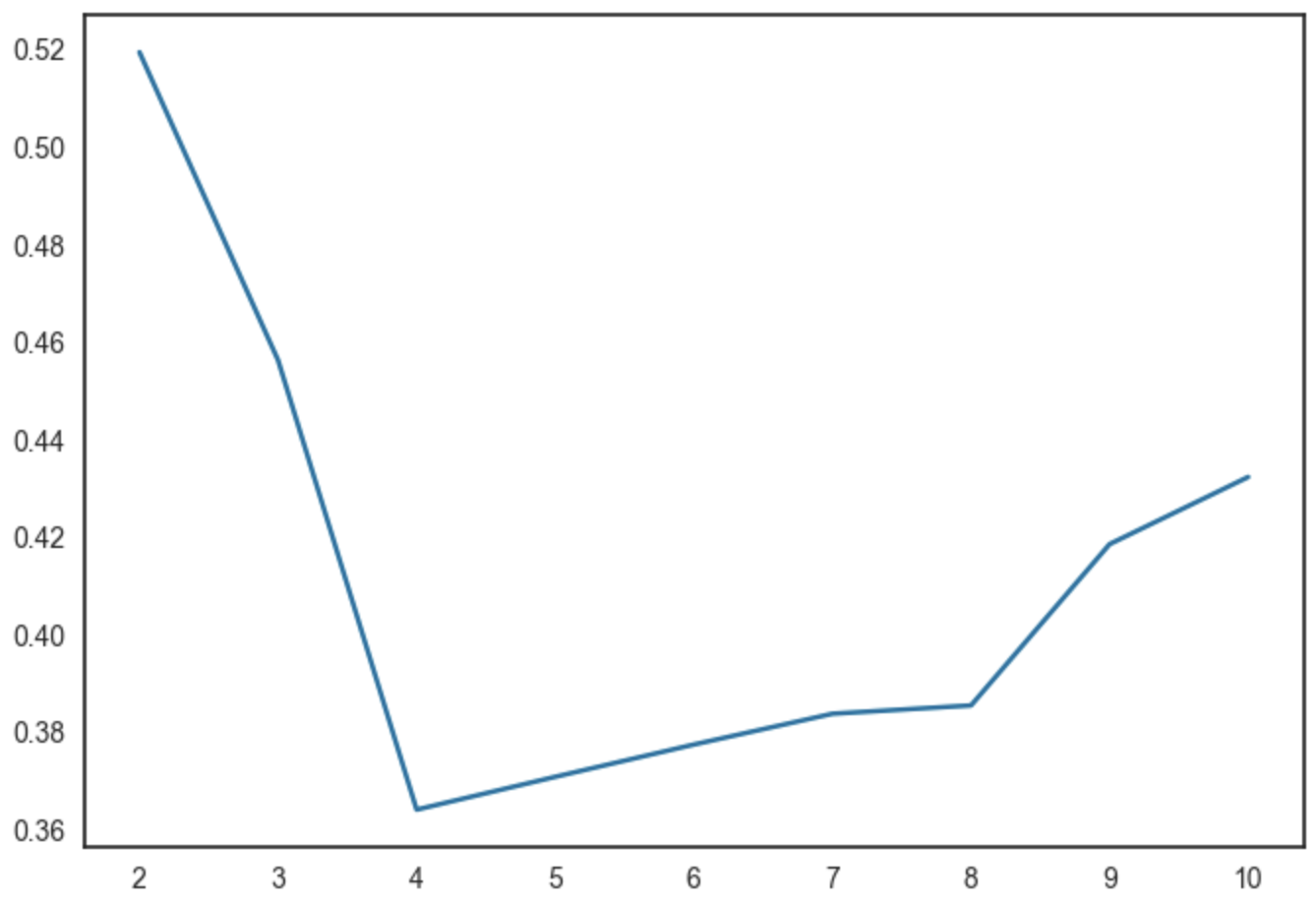
5. 파라미터별 성능 비교
fig, ax = plt.subplots(3,2, figsize=(15,10))
for i in [2,3,4,5,6,7]:
kmeans_model3 = KMeans(init='k-means++',
n_clusters = i,
n_init= 10,
max_iter = 200,
random_state=111)
q, mod = divmod(i,2)
# 실루엣계수 시각화
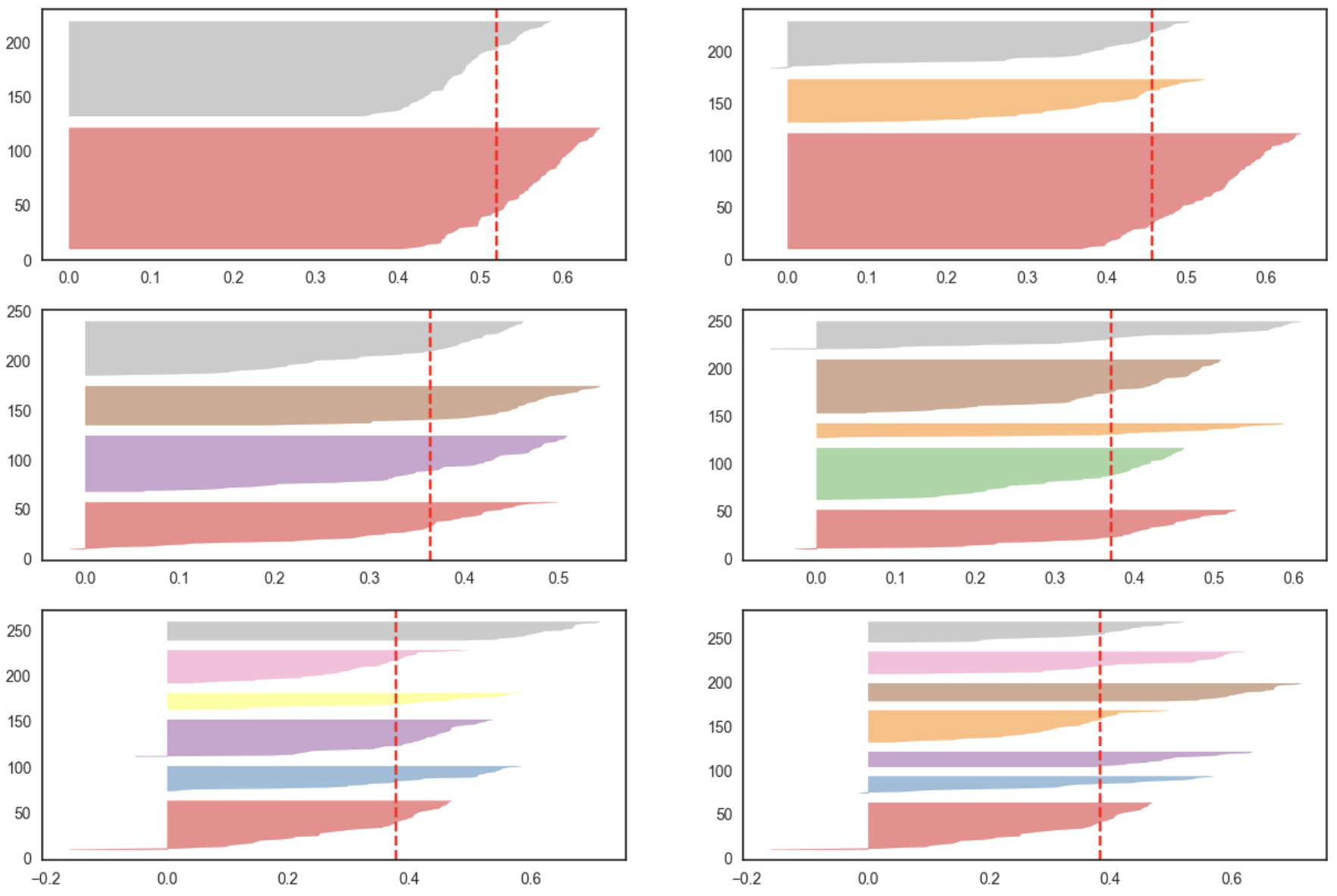
visual = SilhouetteVisualizer(kmeans_model3, color = 'yellowbricks', ax=ax[q-1][mod])
visual.fit(df_mns_sp)
반복문을 사용해 군집의 개수(K)를 다르게 했을 때 실루엣 계수를 시각화해서 파라미터별 성능을 비교한 후 최적의 파라미터를 찾는다.
6. 군집 label 가져오기
kmeans_model1.fit_predict(df_mns_sp)
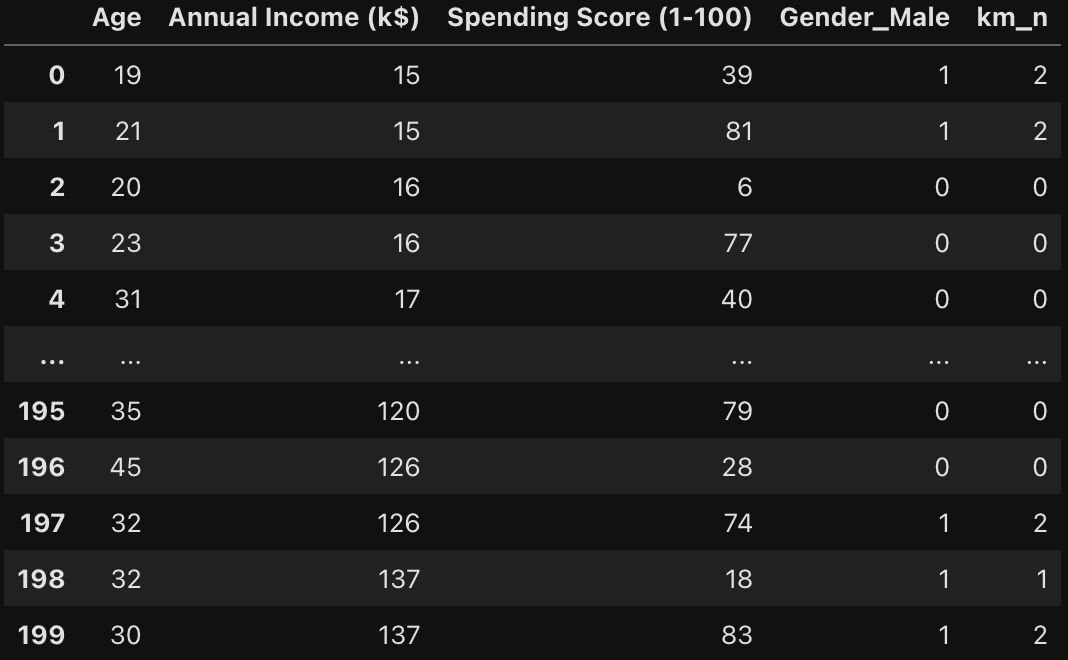
df_sp['km_n']= kmeans_model1.fit_predict(df_mns_sp)
df_sp
군집 label 칼럼을 기존 데이터프레임에 추가해 데이터포인트 별 군집화 결과를 확인할 수 있다.
앞서 살펴본 Kmeans알고리즘처럼 클러스터링을 수행하는 또 다른 알고리즘이 있다. 바로 DBSCAN이다. DBSCAN은 Multi Dimension의 데이터를 밀도 기반으로 서로 가까운 데이터 포인트를 함께 그룹화하는 알고리즘이다.
| 특징 | DBSCAN | K-means |
| Cluster의 모양 | 데이터의 Cluster 모양이 임의적으로 묶이는 경우 잘 Clustering 됨. |
데이터의 Cluster 모양이 구 모양인 경우에 잘 Clustering 됨. |
| Cluster의 갯수 | 군집화 갯수를 미리 정해주지 않아도 됨(밀도 기반) | 군집화될 갯수를 미리 정해줘야함(centroid 기반) |
| Outlier | Clustering에 포함되지 않는 Outlier를 특정할 수 있음 | 모든 데이터가 하나의 Cluster에 포함됨 |
| Initial Setting | 초기 Cluster 상태가 존재하지 않음 | 초기 Centroid 설정에 따라 결과가 많이 달라짐 |
DBSCAN은 일반적으로 K-means Clustering에 비해 1) 불규칙 데이터를 다룰때, 2) Noise와 Outlier가 많을 것으로 예상될 때, 3) 데이터에 대한 사전 예측이 어려울때, 활용하는 것이 좋다.
insurance2 샘플 데이터를 활용해 DBSCAN알고리즘을 실습해보자.
0. 라이브러리 호출
from sklearn.cluster import DBSCAN
# 나이와 bmi 가지고 이상치 찾기
X = df_3[['age','bmi']].values
1. DBSCAN 진행
#DBSCAN 알고리즘 학습
db =DBSCAN(eps=3.0, min_samples =10).fit(X)
2. 이상치 확인
df_3label=db.labels_
pd.Series(df_3label).value_counts() # 26개에 대한 이상치 확인
- 데이터 중, 임의의 포인트를 선택함.
- 선택한 데이터와 Epsilon 거리 내에 있는 모든 데이터 포인트를 찾음.
- 주변에 있는 데이터 포인트 갯수가 Min Points 이상이면, 해당 포인트를 중심으로 하는 Cluster를 생성한다.
- 어떠한 포인트가 생성한 Cluster 안에 존재하는 다른 점 중, 다른 Cluster의 중심이 되는 데이터 포인트가 존재한다면 두 Cluster는 하나의 Cluster로 간주한다.
- 1~4번을 모든 포인트에 대해서 반복한다.
- 어느 Cluster에도 포함되지 않는 데이터 포인트는 이상치로 처리한다.
DBSCAN은 위와 같은 절차를 거치기 때문에 마지막에 클러스터링되지 않은 이상치를 확인할 수 있다.
3. 이상치 시각화
#시각화로 그래프 그리기
plt.figure(figsize=(15,15))
uq_labels = set(df_3label)
color = ['blue','red']
for color, label in zip(color, uq_labels):
sample_mask = [True if l == label else False for l in df_3label]
plt.plot(X[:,0][sample_mask],X[:,1][sample_mask],'o',color=color)
plt.xlabel('Age')
plt.xlabel('bmi')
'Data > Machine Learning' 카테고리의 다른 글
| [ML] 랜덤 포레스트 모델 하이퍼파라미터 튜닝하기 (0) | 2024.06.25 |
|---|---|
| [ML] 평가 지표 (0) | 2024.06.23 |
| [ML] KNN 알고리즘 (0) | 2024.06.22 |
| [ML] Feature Selection (0) | 2024.06.22 |
| [ML] 데이터 스케일링 (0) | 2024.06.05 |


