
짜리몽땅 매거진
[ML] TSP알고리즘으로 최적 노선 추천하기(+ k-means, Gradient Boosting) 본문
제주도의 등하교 버스 혼잡 문제를 개선하고자 정류장별 데이터를 활용해 혼잡한 정류장 예측 모델링을 진행하고 혼잡 지표가 가장 높은 정류장을 선별해 새로운 등하교 버스 노선을 추천해보자.
0. 데이터 수집 및 전처리

위와 같이 데이터를 수집했고, 종속변수는 정류장별 혼잡지표(=정류장별 인근 10대 거주인구수 / 정류장별 버스 개수)로 새로운 파생변수를 생성하였다.
1. 지역 특성 파악을 위한 군집 분석
제주도 버스 정류장 지역의 특성을 파악하기 위하여, 군집화 분석을 진행하였다. 앞서 전처리한 데이터에서 정류장 아이디 기준 평균을 산출하였다. 그리고, 데이터를 정류장, 인구, 학교 세 가지 특성으로 나누어, K-means 알고리즘을 활용해 클러스터링을 3회 진행하였다.
1. ‘정류장’ 특성 군집화
1) 스케일링을 통해 표준화 진행
2) 군집 개수 선택 :Elbow Method 및 군집 개수별 실루엣 계수 산출
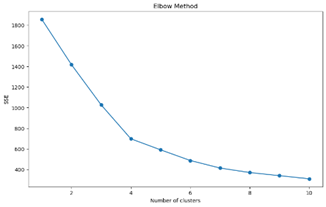
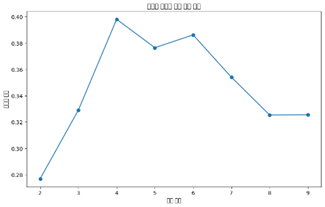
Elbow plot이 꺾이는 지점과 실루엣 계수가 가장 큰 k=4에서 군집 수를 결정하였다.
3) 4개의 군집으로 클러스터링 진행 후 품질 측정을 위해 실루엣 계수 산출
실루엣 계수 : 0.3981164731326448
4) 클러스터링 결과 시각화
주성분 분석을 통해 데이터를 2차원으로 축소하고, 산점도 차트로 시각화
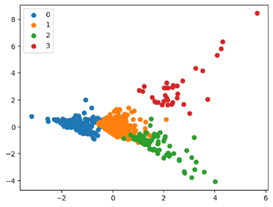
5) 군집별 변수 평균 산출 및 분석
| cluster | 거주인구 | 근무인구 | 방문인구 |
| 0 | - 0.259618 | 1.105759 | - 0.372698 |
| 1 | - 0.144638 | - 0.617947 | - 0.263246 |
| 2 | - 0.219301 | -0.392511 | 2.016615 |
| 3 | 3.346233 | - 0.094894 | - 0.255002 |
1. Cluster 0
버스 운행이 상대적으로 적고, 배차 간격이 길며, 이용자 수도 적은 정류장들로 구성되어 있다. 이는 교통 수요가 낮은 지역이나 교통 서비스가 부족한 지역의 정류들이 포함되어 있을 가능성이 있다.
2. Cluster 1
평균적인 수준이며, 이용자 수도 평균적인 정류장들로 구성되어 있다. 교통 서비스와 수요가 적절한 균형을 이루고 있는 정류장들이 포함되어 있을 것으로 보인다.
3. Cluster 2
버스 운행 수준은 평균보다 약간 낮지만, 배차 간격이 짧고 이용자 수가 매우 많은 정류장들로 구성되어 있다. 이는 교통 수요가 높은 지역의 정류장들이 포함되어 있을 가능성이 높다.
4. Cluster 3
이 군집은 버스 운행 및 배차 간격이 평균적인 수준이며, 이용자 수도 평균적인 정류장들로 구성되어 있다. 교통 서비스와 수요가 적절한 균형을 이루고 있는 정류장들이 포함되어 있을 것으로 보인다.
2. ‘인구’ 특성 군집화
1) 스케일링을 통해 표준화 진행
2) 군집 개수 선택 :Elbow Method 및 군집 개수별 실루엣 계수 산출
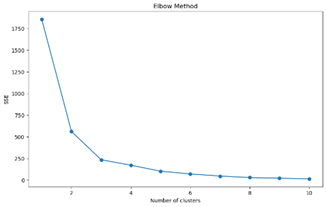
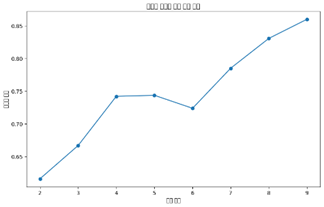
Elbow plot이 k=4 지점에서 꺾이며, 실루엣 계수가 [4,5] 구간에서 증가율이 크게 감소하므로 k=4에서 군집 수를 결정하였다.
3) 4개의 군집으로 클러스터링 진행 후 품질 측정을 위해 실루엣 계수 산출
실루엣 계수 : 0.7546883916945895
4) 클러스터링 결과 시각화
주성분 분석을 통해 데이터를 2차원으로 축소하고, 산점도 차트로 시각화
5) 군집별 변수 평균 산출 및 분석
| cluster | 거주인구 | 근무인구 | 방문인구 |
| 0 | 0.785966 | 1.360057 | 0.424097 |
| 1 | -0.895393 | -0.814699 | -1.018653 |
| 2 | 0.150882 | -0.317615 | 0.910780 |
| 3 | 1.613129 | 1.392197 | 1.272200 |
1. Cluster 0
근무인구가 매우 많은 지역으로 보이며, 거주인구와 방문인구도 평균보다 높은 편이다. 상업 및 업무 지역이 밀집된 지역의 정류장들로 구성되어 있을 가능성이 높다.
2. Cluster 1
세 변수 모두 평균보다 매우 낮은 지역의 정류장들로 구성되어 있다. 이는 상대적으로 인구 밀도가 낮은 지역일 가능성이 높다.
3. Cluster 2
방문인구가 평균보다 매우 높은 지역의 정류장들로 구성되어 있다. 이는 관광지나 상업 시설이 밀집된 지역일 가능성이 높다.
4. Cluster 3
세 변수 모두 평균보다 매우 높은 지역의 정류장들로 구성되어 있습니다. 이는 주거, 상업, 업무 시설이 밀집된 복합 용도 지역일 가능성이 높다.
5. Cluster 3
버스 운행 및 배차 간격이 평균적인 수준이며, 이용자 수도 평균적인 정류장들로 구성되어 있다. 교통 서비스와 수요가 적절한 균형을 이루고 있는 정류장들이 포함되어 있을 것으로 보인다.
3. ‘학교’ 특성 군집화
1) 스케일링을 통해 표준화 진행
2) 군집 개수 선택 :Elbow Method 및 군집 개수별 실루엣 계수 산출
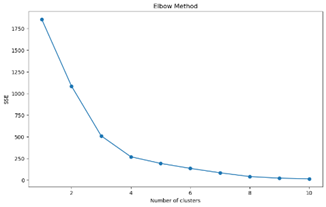
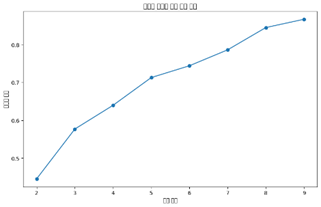
실루엣 계수는 개수에 비례하여 증가하지만 Elbow plot이 k=4 지점에서 꺾이므로 k=4에서 군집 수를 결정하였다.
3) 4개의 군집으로 클러스터링 진행 후 품질 측정을 위해 실루엣 계수 산출
실루엣 계수 : 0.6398179468421463
4) 클러스터링 결과 시각화
주성분 분석을 통해 데이터를 2차원으로 축소하고, 산점도 차트로 시각화
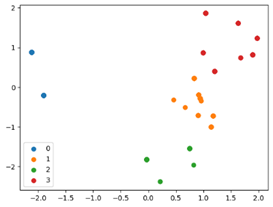
5) 군집별 변수 평균 산출 및 분석
| cluster | 학교수 | 학생수 | 주당수업시수 |
| 0 | 0.416728 | 1.346462 | 0.493763 |
| 1 | -1.183276 | -1.224374 | -0.682372 |
| 2 | 1.421925 | -0.378301 | -1.239274 |
| 3 | -0.668300 | -0.304819 | 0.980685 |
1. Cluster 0
학생 수가 많고 수업 시수도 많은 편으로, 상대적으로 규모가 큰 학교들로 구성되어 있다. 이는 도심 지역의 대규모 학교들일 가능성이 높다.
2. Cluster 1
세 변수 모두 평균보다 낮은 수준으로, 규모가 작은 학교들이 있는 지역일 가능성이 높다.
3. Cluster 2
학교 수는 많지만 학생 수와 수업 시수가 적은 편으로, 학생 수가 적은 교외 지역이나 소규모 학교들이 많은 지역일 가능성이 높다.
4. Cluster 3
학교 수와 학생 수는 적은 편이지만 수업 시수가 많은 편으로, 특성화된 소규모 학교들이 포함된 지역일 가능성이 높다.
2. 데이터 모델링
1. 모델링 데이터셋 클렌징
앞서 버스별, 인구별, 학교별 변수에 따라 3회의 클러스터링 진행한 후 다음과 같은 결론을 내렸다.
|
즉, 위의 결론에 해당하는 정류장일 경우, 하교버스를 이용하려는 수요 대비 버스의 공급이 이미 충분하다는 것이며, 새로운 하교버스 노선으로 부적절한 정류장인 셈이다. 따라서 본 연구는 클러스터링 결과 cluster_버스, cluster_인구, cluster_학교 칼럼이 각각 0, 1, 1인 정류장(행)일 경우 모델링 데이터셋에서 제외하였다.
2. 스케일링
스케일링(Scaling)은 데이터의 값을 일정한 범위로 변환하는 과정으로, 준비된 데이터셋을 모델링에 적합한 형태로 만들고 모델의 성능을 향상시키기 위해 진행했다. 데이터 값을 평균이 0, 표준편차가 1이 되도록 변환하고. 주로 Z-스코어 표준화 방법을 사용하는 StandardScaler를 사용해 독립변수들을 표준화하였다.
3. 모델링
종속변수(정류장별 인근 10대 거주인구 수 / 정류장별 버스 개수)를 회귀모델을 활용해 예측하고 선형회귀모델인 Linear Regression, Ridge Regression, Lasso Regression, ElasticNet Regression과 비선형회귀모델인 Decision Tree Regression, Random Forest Regression, Gradient Boosting Regression, Support Vector Regression, XGBoost Regression 총 9개의 모델을 활용하였다.
모델의 성능을 개선하고자 GridSearchCV를 활용하였는데, GridSearchCV의 경우 교차검증과 하이퍼파라미터 튜닝을 동시에 진행하는 방법론으로 모델의 성능을 최적화하고 과적합을 방지한다.
모델을 학습시키고 GridSearchCV까지 진행한 결과 회귀모델별 성능 지표는 아래와 같다.
(선형 회귀 모델)
| Linear Regression |
Ridge Regression |
Lasso Regression |
ElasticNet Regression |
|
| Best Parameter | {} | {'alpha': 10.0} | {'alpha': 10.0} | {'alpha': 0.1, 'l1_ratio': 0.5} |
| MSE | 27119441 | 269161458.235 | 270811476.372937 | 268491946.60872 |
| MAE | 12568.951 | 12505.6538877 | 12549.2363009238 | 12499.491263321 |
| RMSE | 16467.981 | 16406.1408696 | 16456.3506395840 | 16385.723865875 |
| R-squared | 0.4873739 | 0.49121672700 | 0.48809777515597 | 0.4924822734157 |
(비선형 회귀 모델)
| Decision Tree Regression |
Random Forest Regression |
Gradient Boosting Regression |
XGBoost Regression |
|
| Best Parameter | {'max_depth': 10} | {'max_depth': 10, 'n_estimators': 100} | {'learning_rate': 0.1, 'n_estimators': 50} | {‘learning_rate': 0.1, 'max_depth': 3} |
| MSE | 249847356.41 | 217922441.7816 | 199658466.2214 | 209325689.3756 |
| MAE | 9930.5990526 | 9444.174697001 | 9964.841594865 | 9962.757726762 |
| RMSE | 15806.560549 | 14762.19637390 | 14130.05542174 | 14468.09211249 |
| R-squared | 0.527725267 | 0.58807143520 | 0.622594971097 | 0.604321472843 |
R-squared 값이 가장 1에 근접한 모델인 Gradient Boosting Regression을 최종모델로 선정하였다.
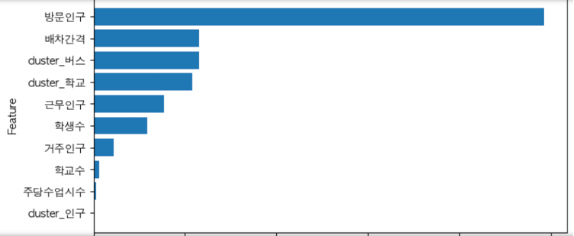
최종모델이 예측에 끼친 영향을 파악하고자 feature_importances_를 활용해 변수중요도를 출력하였다. 정류장 인근 10대 방문인구가 가장 큰 영향을 끼침을 확인할 수 있었다.
4. 위경도별 정류장 클러스터링
이후 종속변수(정류장별 인근 10대 거주인구 수 / 정류장별 버스 개수) 예측값 중 상위 10% 정류장을 하교버스 추진이 시급하며, 혼잡한 정류장이라 판단하였다. 추출한 상위 10% 정류장을 각각의 정류장 위경도 데이터와 매핑하였고, 학군별 하교버스 노선을 추천하고자 위경도에 따라 클러스터링을 한 번 더 실시하였다. 상위 10% 정류장 중에는 앞서 언급한 신성여중, 신성여고 인근의 정류장이 모두 포함되었으며, 문제해결이 우선적으로 필요한 지역으로 판단하여, 인근 7개 정류장은 하나의 클러스터로 분류하였다.
1) 스케일링을 통해 표준화 진행
2) 군집 개수 선택 :Elbow Method 및 군집 개수별 실루엣 계수 산출
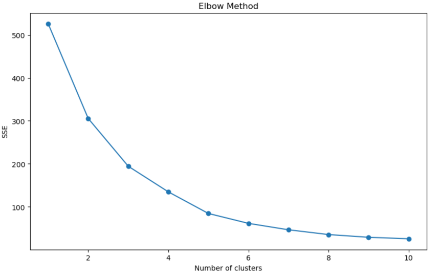
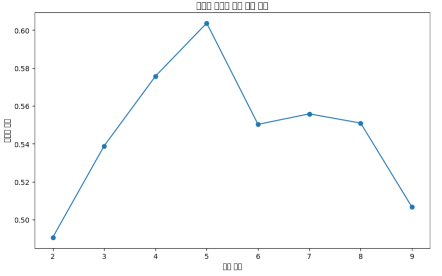
Elbow plot이 꺾이는 지점과 실루엣 계수가 가장 큰 k=5에서 군집 수를 결정하였다.
3) 4개의 군집으로 클러스터링 진행 후 품질 측정을 위해 실루엣 계수 산출
실루엣 계수 : 0.536956700327757
4) 클러스터링 결과 시각화
주성분 분석을 통해 데이터를 2차원으로 축소하고, 산점도 차트로 시각화
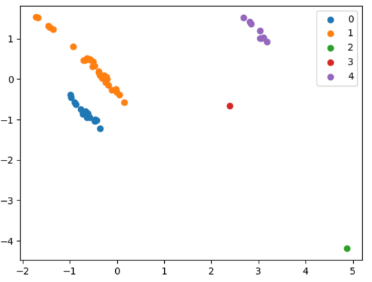
3, 4 군집과 같은 경우 하나의 데이터 포인트씩 다른 위경도에 위치하여 버스 노선 구축에 부적합하다고 판단하고 0, 1, 2 군집을 바탕으로 학군별 순환버스 노선 추천을 진행하였다.
5. TSP 알고리즘을 활용한 학군별 순환등교버스 노선 구축
import pandas as pd
import numpy as np
from scipy.spatial.distance import cdist
from scipy.optimize import linear_sum_assignment
import folium
import networkx as nx
df = pd.read_excel('상위 10퍼 정류장_최종.xlsx')
df
# 각 클러스터별로 TSP 문제 해결 및 원형 경로 생성
def solve_tsp(coords):
# 거리 행렬 계산
dist_matrix = cdist(coords, coords, metric='euclidean')
G = nx.from_numpy_array(dist_matrix)
# 최소 비용의 TSP 경로 찾기
tsp_path = nx.approximation.traveling_salesman_problem(G, cycle=True)
ordered_coords = coords[tsp_path]
return ordered_coords
results = {}
# 클러스터별로 TSP 해결 및 원형 경로 생성
for cluster in df['cluster'].unique():
cluster_coords = df[df['cluster'] == cluster][['위도', '경도']].values
if len(cluster_coords) < 2:
continue # 클러스터에 데이터가 없거나 하나만 있으면 건너뛰기
tsp_route = solve_tsp(cluster_coords)
results[cluster] = tsp_route
map_ = folium.Map(location=[33.5, 126.5], zoom_start=11)
colors = ['red', 'blue', 'green', 'purple', 'orange', 'darkred', 'lightred', 'beige', 'darkblue', 'darkgreen', 'cadetblue', 'darkpurple', 'white', 'pink', 'lightblue']
for cluster, route in results.items():
route_line = [(coord[1], coord[0]) for coord in route] # 위도와 경도를 (위도, 경도)로 변환
folium.PolyLine(route_line, color=colors[cluster % len(colors)], weight=2.5, opacity=1).add_to(map_)
for coord in route:
folium.Marker(location=[coord[1], coord[0]], icon=folium.Icon(color=colors[cluster % len(colors)])).add_to(map_)
map_TSP 알고리즘은 TSP(Traveling Salesman Problem, 외판원 문제)는 몇 개의 도시를 한 번씩 방문하여 출발한 도시로 돌아오는 최단 경로를 찾는 알고리즘으로, 학군(=위경도)별로 클러스터링된 정류장이 원형 순환버스 노선 형태로 갖춰지도록 알고리즘을 개선하였다. 그 결과 위경도별 정류장과 TSP 알고리즘을 통해 구축된 학군별 순환버스 노선은 아래 맵과 같다. TSP 알고리즘 특성상 각 포인트별 최단 직선거리로 노선을 구축하기에 실제 제주도 도로까지 반영하진 못하는 한계점이 존재하지만, 그려진 노선의 인근 도로로 노선을 구축한다면 한계점을 해소할 수 있을 것이다.
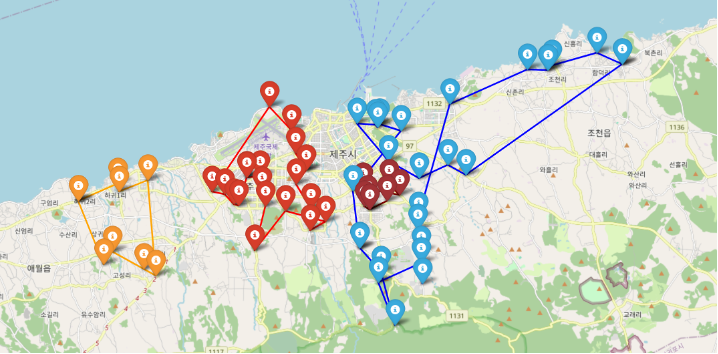
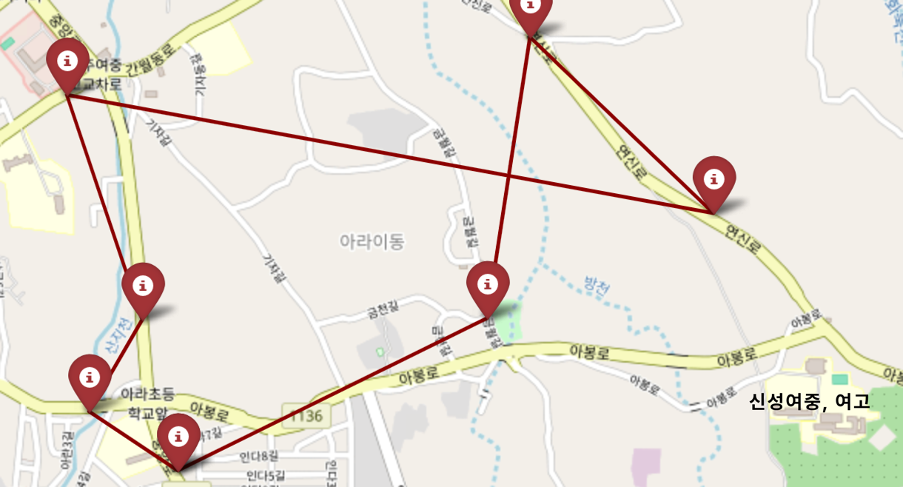
TSP알고리즘 코드를 포함한 클러스터링, 모델링 코드는 아래 첨부하였다.
GitHub - kookguk/Doldam_schoolbus_DA: 2024 제주 공공데이터 활용 창업경진대회
2024 제주 공공데이터 활용 창업경진대회. Contribute to kookguk/Doldam_schoolbus_DA development by creating an account on GitHub.
github.com
'Data > Machine Learning' 카테고리의 다른 글
| [ML] Kmeans 알고리즘 + DBSCAN (2) | 2024.08.11 |
|---|---|
| [ML] Feature Selection (7) | 2024.07.31 |
| [ML] 랜덤 포레스트 모델 하이퍼파라미터 튜닝하기 (0) | 2024.06.25 |
| [ML] 평가 지표 (0) | 2024.06.23 |
| [ML] KNN 알고리즘 (0) | 2024.06.22 |


