
짜리몽땅 매거진
[LLM] Transformer - Attention, Self Attention 본문
지난 글에서 LLM의 정의와 LLM의 기반인 트랜스포머 모델 중 앞단인 임베딩과 포지셔널 인코딩에 대해 알아보았는데, 이번에는 인코더와 디코더의 중요한 부분을 차지하는 '셀프 어텐션(Self Attention)'에 대해 알아보자.
셀프어텐션을 알아보기 이전에, '어텐션(Attention)' 매커니즘을 먼저 알아야 셀프어텐션을 이해할 수 있다.
Attention

인코더는 입력으로 input data를 받아 압축 데이터(context vector)로 변환 및 출력해주는 역할을 한다. 디코더는 반대로 압축 데이터(context vector)를 입력 받아 output data를 출력해준다. 이는 우리가 사용하는 전화기의 원리와 동일한데, 이렇게 해주는 이유는 정보를 압축하므로써 연산량을 최소화하기 위해서이다. 하지만 전통적인 언어 모델들은 위 그림처럼 문맥 벡터가 Encoder의 마지막 RNN 셀에서만 나오므로 그 전 RNN셀들의 반영이 되지 않았다. 이렇게 문맥 벡터를 사용하면 연산량이 줄어든다는 장점이 있지만 정보의 손실이 발생하는 문제점 역시 발생하게 된다. 이러한 정보 손실 문제를 해결하기 위해 '어텐션(Attention)'이라는 개념이 도입되었다.
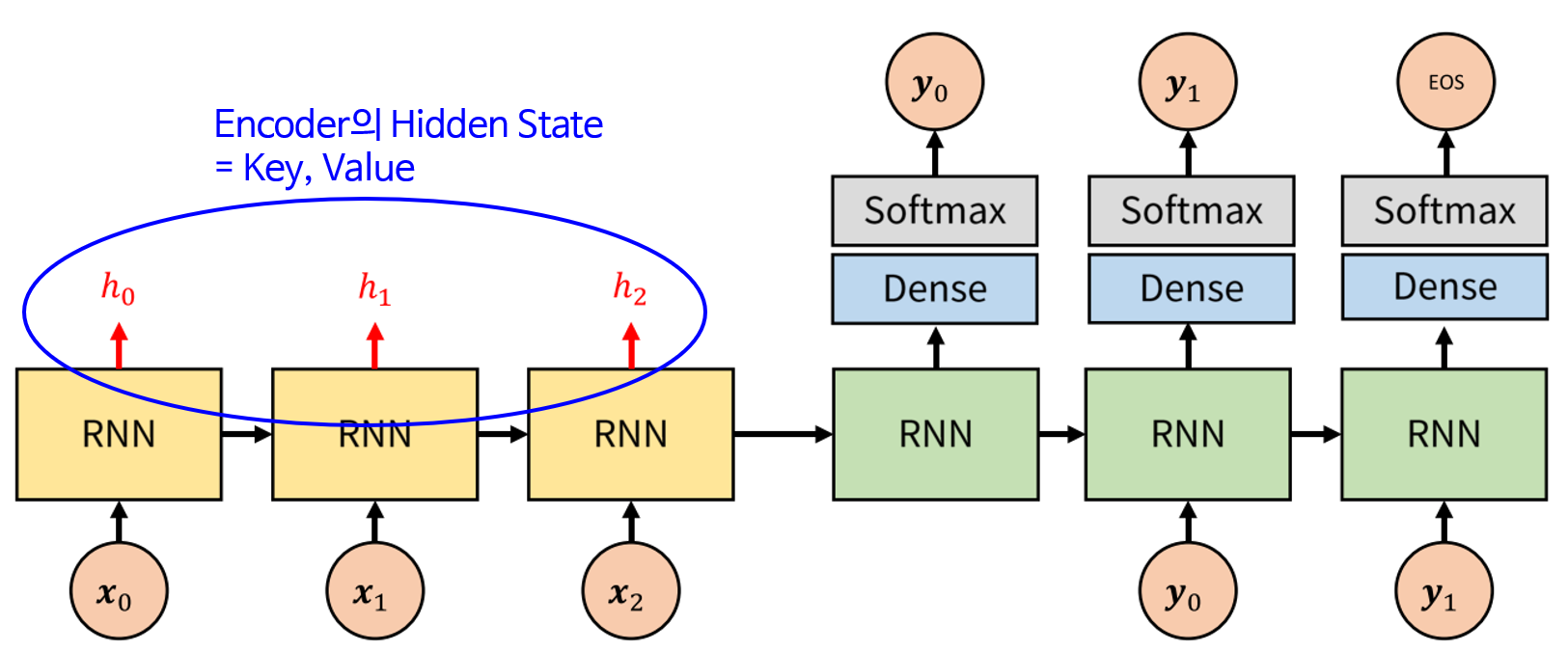
어텐션 매커니즘의 경우 output으로 hidden state가 나오는 것을 알 수 있다. 이 때문에 인코더와 디코더 구조에서 각각의 output이 hidden state의 형태로 출력된다. 인코더의 hidden states와 디코더의 hidden state을 이용해 Attention score를 구해준다. hidden state는 행렬이므로 위의 임코더 hidden states들과 디코더 hidden state를 내적(dot product)해주면 상수 값이 나오게 된다. 이 score들을 Attention score라고 부른다.
이제 Attention score들을 softmax 활성 함수(activation function)에 대입하여 Attention distribution을 만들어준다. softmax함수는 어떤 변수를 0 ~ 1 사이의 값으로 만들어주는데, 즉 Attention score들을 확률분포로 변환하는 것이다. 최종적으로 인코더 hidden states들을 방금 구한 Attention distribution에 곱하여 합해주어 Attention value 행렬을 만들어준다. 즉 각 문맥들(hidden states)의 중요도(Attention score)를 반영하여 최종 문맥(Attention value)을 구한다고 생각하면 된다.
Self Attention

'Self Attention'이란 말 그대로 Attention을 자기 자신한테 취한다는 것이다. 셀프 어텐션에서는 Query, Key, Value 라는 3가지 변수가 존재하는데, 모두 동일한 임베딩 벡터에서 도출된다. 어텐션과의 차이점은 어텐션의 경우, hidden layer 연산 결과 hidden state vector를 다음 Layer에 적용 시키는 방식으로 이전 단어의 정보를 전달한다. 결국 어텐션은 hidden layer가 쌓여감에 따라 초기 해석 정보가 어쩔수 없이 사라지게 된다. 셀프 어텐션의 경우, 인코더는 모든 단어에 대해, 디코더는 직전 예측 단어에 대해 Q(=Query)를 구하여 해당 값을 활용하기 때문에 각 단어에 대한 온전한 연산이 수행되어 초기 정보가 온전히 반영될 수 있게 된다.
어텐션과 작동 원리는 유사하지만 약간의 차이를 정리한 연산 과정은 아래와 같다.
1) input 단어들을 활용해 embedding vector를 도출
2) embedding vector를 활용해 Q,K,V 생성
3) Q,K 내적을 통해 attention score를 계산(연관성이 높은 단어일수록 가중치 up)
4) attention score에 softmax 함수 적용
5) 4번 연산 결과값들을 V와 곱셈
이를 통해 도출된 셀프어텐션 Value 값은 각 단어 간 연관 관계를 반영하게 되는데, 이 값을 통해 어떤 단어에 가중을 두어 더 많은 정보를 반영할지 결정할 수 있게 된다.
'Data > Deep Learning' 카테고리의 다른 글
| [LLM] Hugging Face Transformers 라이브러리 실습 (0) | 2025.02.18 |
|---|---|
| [LLM] Transformer - Masked Multi-Head Attention, Residual Connection (0) | 2025.02.05 |
| [LLM] Transformer - Embedding, Positional Encoding (1) | 2025.01.30 |
| [DL] GRU, LSTM 모델로 시계열 분석하기 (1) | 2024.12.27 |


