
짜리몽땅 매거진
[금융 AI] AI 기반의 신용 리스크 모델링(3) - 머신러닝 기반 신용 평가 모델 본문
머신러닝 기반의 신용 평가 모델링을 진행하고자 두 가지 데이터셋을 준비한다.
- 아메리칸 익스프레스 주최 파산 예측 경진대회 데이터셋(https://www.kaggle.com/competitions/amex-default-prediction/data)
- 홈 크레딧 경진대회 데이터셋(https://www.kaggle.com/c/home-credit-credit-risk-model-stability/data)
두 데이터셋은 실제 금융 데이터에 기반을 둔 광범위 데이터이기 때문에 실습 편의를 위해 데이터를 고객당 하나의 행을 가진 데이터 테이블 형식으로 변환하고, 그 중에서 10만 개의 행을 임의 추출하여 사용할 예정이다.
import numpy as np
import pandas as pd
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
import warnings
warnings.filterwarnings('ignore', module='sklearn.metrics.cluster')
df = pd.read_pickle('/kaggle/input/amex-data-sampled/train_df_sample.pkl')
df = df.reset_index()
df.head()
불러온 데이터에 대해 EDA를 진행하고, 결측치 처리 작업을 진행한다. 위는 Amex prediction default 데이터를 한 명의 고객 단위로 피벗하고 10만 개를 샘플링한 데이터다. 해시된 ID값이 보이는데, 이렇게 긴 문자열은 메모리 사용량에 영향을 주므로 필요한 만큼만 인코딩해서 사용한다.
import hashlib
def encode_customer_id(id_str):
encoded_id = hashlib.sha256(id_str.encode('utf-8')).hexdigest()[:16]
return encoded_id
df['customer_ID'] = df['customer_ID'].apply(encode_customer_id)
def drop_null_cols(df, threshold=0.8):
"""
데이터프레임에서 결측치 비율이 threshold 이상인 변수를 제거하는 함수
"""
null_percent = df.isnull().mean()
drop_cols = list(null_percent[null_percent >= threshold].index)
df = df.drop(drop_cols, axis=1)
print(f"Dropped {len(drop_cols)} columns: {', '.join(drop_cols)}")
return df
df = drop_null_cols(df)
먼저 결측치 비율이 높은 변수를 제거하자. 결측치 제거를 위해 위처럼 별도의 함수를 만들어도 되고, 변수 선택 부분에서 추가하거나 오픈 라이브러리를 사용해도 좋다.
cat_features = [
"B_30",
"B_38",
"D_114",
"D_116",
"D_117",
"D_120",
"D_126",
"D_63",
"D_64",
"D_68"
]
cat_features = [f"{cf}_last" for cf in cat_features]
import random
num_cols = df.select_dtypes(include=np.number).columns.tolist()
num_cols = [col for col in num_cols if 'target' not in col and col not in cat_features]
num_cols_sample = random.sample([col for col in num_cols if 'target' not in col], 100)
변수가 너무 많기 때문에 범주형 변수와 100개의 수치형 변수를 임의로 선택한다.
feature_list = num_cols_sample + cat_features
all_list = feature_list + ['target']
df = df[all_list]
def summary(df):
print(f'data shape: {df.shape}')
summ = pd.DataFrame(df.dtypes, columns=['data type'])
summ['#missing'] = df.isnull().sum().values
summ['%missing'] = df.isnull().sum().values / len(df)* 100
summ['#unique'] = df.nunique().values
desc = pd.DataFrame(df.describe(include='all').transpose())
summ['min'] = desc['min'].values
summ['max'] = desc['max'].values
summ['first value'] = df.loc[0].values
summ['second value'] = df.loc[1].values
summ['third value'] = df.loc[2].values
return summ
summary(df)
요약 테이블은 데이터 정보를 한 눈에 볼 수 있도록 해준다. 직접 함수를 구현했는데, pandas-profiling 등의 데이터프레임 요약 통계 정보 생성 라이브러리를 사용해도 좋다.
import gc
gc.collect()
--> 547
gc.collect()는 파이썬의 가비지 컬렉터(Garbage Collector)를 명시적으로 호출하여 메모리를 회수하는 역할을 한다. 가비지 컬렉터는 더 이상 사용되지 않는 객체들을 자동으로 메모리에서 해제하는 파이썬의 기능이다.
gc.collect()를 호출하는 이유는 다음과 같다:
1) 메모리 관리: 파이썬은 동적 메모리 할당 및 해제를 처리하기 때문에, 메모리 관리가 중요하다. gc.collect()를 사용하여 더 이상 필요하지 않은 객체들을 메모리에서 제거함으로써 메모리 사용량을 최적화할 수 있다.
2) 메모리 누수 방지: 가비지 컬렉터는 메모리 누수를 방지하기 위해 사용될 수 있다. 메모리 누수란 더 이상 사용되지 않는 객체들이 메모리에 남아있어 메모리 사용량이 계속해서 증가하는 현상을 말한다. gc.collect()를 호출하여 메모리에서 제거되지 않은 객체들을 강제로 회수함으로써 메모리 누수를 방지할 수 있다.
3) 성능 개선: 가비지 컬렉터는 메모리 회수에 관여하므로, 불필요한 객체들을 빠르게 회수함으로써 프로그램의 전반적인 성능을 향상시킬 수 있다.
gc.collect()는 일반적으로 명시적으로 호출할 필요가 없으며, 파이썬 인터프리터가 자동으로 가비지 컬렉션을 수행한다. 하지만 특정 시점에서 메모리를 즉시 회수하고자 할 때 사용될 수 있다. 주로 대규모 데이터 처리나 장기간 실행되는 프로그램에서 메모리 사용을 최적화하기 위해 사용된다.
df[cat_features].dtypes
-->
df[cat_features].dtypes
B_30_last float16
B_38_last float16
D_114_last float16
D_116_last float16
D_117_last float16
D_120_last float16
D_126_last float16
D_63_last category
D_64_last category
D_68_last float16
dtype: object
for categorical_feature in cat_features:
if df[categorical_feature].dtype == 'float16':
df[categorical_feature] = df[categorical_feature].astype(str)
if df[categorical_feature].dtype == 'category':
df[categorical_feature] = df[categorical_feature].astype(str)
elif df[categorical_feature].dtype == 'object':
df[categorical_feature] = df[categorical_feature].astype(str)
데이터 타입을 살펴보았을 때, 위와 같이 범주형 변수의 데이터 타입이 다양할 경우 데이터 처리 작업에서 오류가 발생할 가능성이 높다. 따라서 위 for문을 통해 범주형 변수의 데이터 타입을 통일해준다.
from sklearn.preprocessing import LabelEncoder
from sklearn.impute import SimpleImputer
le_encoder = LabelEncoder()
for categorical_feature in cat_features:
df[categorical_feature].fillna(value='NaN', inplace=True)
df[categorical_feature] = le_encoder.fit_transform(df[categorical_feature])
def impute_nan(df, num_cols, strategy='mean'):
imputer = SimpleImputer(strategy=strategy)
df[num_cols] = imputer.fit_transform(df[num_cols])
return df
df = impute_nan(df,num_cols_sample, strategy="mean")
위는 추가로 결측치를 처리하는 과정이다. LabelEncoder를 사용해 범주형 변수를 숫자로 인코딩한다. 이러면 각 범주형 값들은 고유 정수로 변하게 된다. 즉 여기서는 결측치를 하나의 고유한 값으로 처리한 것이다.
그 다음으로 SimpleImputer를 사용해 수치형 변수의 결측치를 처리한다. 여기서는 기본값으로 평균(mean)을 사용한다.
이렇게 전반적인 전처리가 마무리됐다면 시각화를 통해 데이터를 파악한다.
# 각 변수 분포 시각화
import seaborn as sns
import matplotlib.pyplot as plt
import math
sns.set(style="whitegrid")
fig, axs = plt.subplots(math.ceil(len(cat_features)/2), 2, figsize=(20, 30))
for i, feature in enumerate(cat_features):
row = i // 2
col = i % 2
sns.countplot(x=feature, data=df, ax=axs[row, col])
axs[row, col].set_xlabel(feature)
axs[row, col].set_ylabel("Count")
sns.despine()
plt.show()
# 각 피처의 타겟 분포
exp_cols = random.sample(num_cols_sample, k=4)
# num_data = train_data.select_dtypes(exclude=['object']).copy()
plt.figure(figsize=(14,10))
for idx,column in enumerate(exp_cols):
plt.subplot(3,2,idx+1)
sns.histplot(x=column, hue="target", data=df,bins=30,kde=True,palette='YlOrRd')
plt.title(f"{column} Distribution")
plt.ylim(0,100)
plt.tight_layout()
4개의 변수만 시각화해보았는데, 각 변수가 타겟(0또는 1)에 따라 어떻게 분포하는지 살펴볼 수 있다. 각 분포가 상이할수록 예측력이 높을 것이라 기대할 수 있다.
이제 WoE와 IV값을 계산하려는데, 그 전에 WoE와 IV가 뭔지 알아보자.
WoE(Weight of Evidence)와 IV(Information Value)는 주로 신용평가 모델이나 이진 분류 문제에서 변수 선택과 변환에 사용되는 통계 기법dl다. 특히 로지스틱 회귀 모델에 적합하다.

WoE (Weight of Evidence)
WOE는 범주형 변수 또는 구간화된 연속형 변수의 각 범주가 타겟 변수(이진 변수)와 얼마나 관련 있는지를 수치화한 값이다.
📌 WoE 계산 공식
- Good = 타깃 값이 0인 케이스 수
- Bad = 타깃 값이 1인 케이스 수
- i : 해당 범주 또는 구간
👉 해석
- WOE > 0: 해당 구간에 좋은 비율이 높다 → 긍정적인 신호
- WOE < 0: 나쁜 비율이 높다 → 부정적인 신호
- WOE = 0: Good/Bad 비율이 전체와 같다 → 설명력 없음
IV (Information Value)
IV는 해당 변수 전체가 목표변수를 예측하는 데 얼마나 유용한지를 나타내는 지표이다. WoE 값에 기반하여 계산된다.
✅ IV 해석 기준
| < 0.02 | 거의 무의미 |
| 0.02 ~ 0.1 | 약한 예측력 |
| 0.1 ~ 0.3 | 보통 수준 |
| 0.3 ~ 0.5 | 강한 예측력 |
| > 0.5 | 너무 강함 (의심 필요) |
WOE/IV를 사용하는 이유
- 모델 성능 향상: 변수 값을 WOE 변환하면 로지스틱 회귀 모델은 변수 간 선형 관계를 더 잘 포착함.
- 결측값 처리와 범주 처리 용이: 결측값을 하나의 범주로 취급해 처리 가능
정리하자면 IV는 변수의 중요도를 평가해서 변수 선택에 사용할 수 있고, WoE는 변수의 값 자체를 변환해서 모델 입력값으로 사용할 수 있다.
def calculate_woe_iv(df, feature_list, cat_features, target):
result_df = pd.DataFrame(columns=['Feature', 'Bins', 'WOE', 'IV', 'IV_sum'])
selected_features = [] # 선택된 피처들을 저장할 리스트
bin_edges_dict = {} # 피처별 bin 경계값을 저장할 딕셔너리
woe_dict = {} # 피처별 WOE 값을 저장할 딕셔너리
for feature in feature_list:
if feature in cat_features: # 피처가 범주형일 경우
df_temp = df.copy()
df_temp[feature + '_bins'] = df_temp[feature] # 범주형 변수의 고유값들을 bin으로 사용
bin_edges_dict[feature] = sorted(df[feature].unique()) # 피처의 고유값들을 bin 경계값으로 저장
else: # 피처가 연속형일 경우
df_temp = df.copy()
df_temp[feature + '_bins'], bin_edges = pd.qcut(df_temp[feature], 10, duplicates='drop', retbins=True)
bin_edges_dict[feature] = bin_edges # 피처를 10개의 bin으로 분할하고 bin 경계값을 저장
# 피처의 각 bin에서 이벤트와 비이벤트의 개수 계산
grouped_data = df_temp.groupby(feature + '_bins')[target].agg([
('non_event', lambda x: sum(1 - x)), # 비이벤트(0)의 개수를 합산
('event', lambda x: sum(x)) # 이벤트(1)의 개수를 합산
]).reset_index()
# 비이벤트와 이벤트의 비율 계산
grouped_data['non_event_prop'] = grouped_data['non_event'] / sum(grouped_data['non_event'])
grouped_data['event_prop'] = grouped_data['event'] / sum(grouped_data['event'])
# WOE(Weight of Evidence)계산
grouped_data['WOE'] = np.where(
grouped_data['event_prop'] == 0,
0,
np.log(grouped_data['non_event_prop'] / grouped_data['event_prop'])
)
# Information Value(IV) 계산
grouped_data['IV'] = (grouped_data['non_event_prop'] - grouped_data['event_prop']) * grouped_data['WOE']
iv_sum = sum(grouped_data['IV'])
if iv_sum >= 0.02: # IV 합이 0.02 이상인 경우 피처를 선택
selected_features.append(feature)
result = pd.DataFrame()
result['Feature'] = [feature] * len(grouped_data)
result['Bins'] = grouped_data[feature + '_bins']
result['WOE'] = grouped_data['WOE']
result['IV'] = grouped_data['IV']
result['IV_sum'] = [iv_sum] * len(grouped_data)
result_df = pd.concat([result_df, result])
woe_dict[feature] = grouped_data.set_index(feature + '_bins')['WOE'].to_dict()
# 선택된 피처들의 개수와 목록 출력
print("전체 피처 개수:", len(feature_list))
print("선택된 피처 개수:", len(selected_features))
print("선택된 피처:", selected_features)
return result_df, selected_features, bin_edges_dict, woe_dict
def transform_to_woe(df, selected_features, cat_features, bin_edges_dict, woe_dict, target):
df_woe = df[selected_features + [target]].copy()
for feature in selected_features:
if feature in cat_features:
# 범주형 피처의 경우, 해당 피처의 WOE 값을 매핑합니다.
df_woe[feature] = df_woe[feature].map(woe_dict[feature])
else:
# 연속형 피처의 경우, bin 경계값에 따라 WOE 값을 할당합니다.
feature_bins = pd.cut(df_woe[feature], bins=bin_edges_dict[feature], include_lowest=True)
df_woe[feature] = feature_bins.map(woe_dict[feature])
return df_woe
df_woe = transform_to_woe(df, selected_features, cat_features, bin_edges_dict, woe_dict, 'target')
df_woe.head()
WoE와 IV값 계산 후 df_woe 데이터프레임을 새로 생성해, selected_features 및 타겟 변수를 포함시킨다. 만약 selected_features가 cat_features에 속한다면 해당 특성의 모든 값을 woe_dict를 사용해 WoE값으로 매핑한다. 혹은 연속형 변수라면, bin_edges_dict에 정의된 구간(bins)를 기반으로 pd.cut 함수를 사용해 구간화한다. 그리고 이 구간들을 woe_dict를 사용해 WoE값으로 매핑한다. 이 함수는 WoE로 변환된 새로운 데이터프레임 df_woe를 반환하게 된다.

이제 Feature Engineering과 전처리를 마무리했으니 XGBoost 분류기 알고리즘을 사용해 모델링을 해보자.
from sklearn.model_selection import StratifiedKFold
from xgboost import XGBClassifier
from sklearn.metrics import roc_auc_score
def xgboost_model(df_woe, target, folds=5, seed=2023):
xgb_models = [] # XGBoost 모델들을 저장할 리스트
xgb_oof = [] # out-of-fold 예측 결과를 저장할 리스트
predictions = np.zeros(len(df_woe)) # 전체 데이터셋에 대한 예측 결과를 저장할 배열
f_imp = [] # 특성 중요도를 저장할 리스트
X = df_woe.drop(columns=[target]) # 독립 변수 데이터
y = df_woe[target] # 종속 변수 데이터
skf = StratifiedKFold(n_splits=folds, shuffle=True, random_state=seed)
for fold, (train_idx, val_idx) in enumerate(skf.split(X, y)):
print(f'{"#"*24} Training FOLD {fold+1} {"#"*24}')
X_train, y_train = X.iloc[train_idx], y.iloc[train_idx]
X_valid, y_valid = X.iloc[val_idx], y.iloc[val_idx]
watchlist = [(X_train, y_train), (X_valid, y_valid)]
model = XGBClassifier(n_estimators=1000, n_jobs=-1, max_depth=4, eta=0.2, colsample_bytree=0.67)
model.fit(X_train, y_train, eval_set=watchlist, early_stopping_rounds=300, verbose=0)
val_preds = model.predict_proba(X_valid)[:, 1] # 검증 세트에 대한 예측 확률
val_score = roc_auc_score(y_valid, val_preds) # 검증 세트의 ROC AUC 점수
best_iter = model.best_iteration
idx_pred_target = np.vstack([val_idx, val_preds, y_valid]).T # 검증 세트 인덱스, 예측 확률, 실제 타겟 값으로 구성된 배열
f_imp.append({i: j for i, j in zip(X_train.columns, model.feature_importances_)}) # 특성 중요도 저장
print(f'{" "*20} auc:{val_score:.5f} {" "*6} best iteration:{best_iter}')
xgb_oof.append(idx_pred_target) # out-of-fold 예측 결과 추가
xgb_models.append(model) # 학습된 모델 추가
if val_score > 0.917:
predictions += model.predict_proba(X)[:, 1] # 특정 조건을 만족하는 모델의 예측 확률을 누적
predictions /= folds # folds 수로 나눠 평균 예측 확률 계산
mean_val_auc = np.mean([roc_auc_score(oof[:, 2], oof[:, 1]) for oof in xgb_oof]) # 평균 out-of-fold ROC AUC 점수 계산
print('*'*45)
print(f'Mean AUC: {mean_val_auc:.5f}')
return xgb_models, xgb_oof, predictions, f_imp
def convert_category_to_numeric(df):
for col in df.columns:
if str(df[col].dtype) == 'category':
df[col] = df[col].astype('int')
return df
df_woe = convert_category_to_numeric(df_woe)
xgb_models, xgb_oof, predictions, f_imp = xgboost_model(df_woe, 'target', folds=5, seed=2023)
XGB 모델에 적합할 수 있도록 category 변수를 변환하고, 앞서 만든 카테고리 변수를 수치 변수로 변환하는 함수를 적용해준다. 그 이후 folds는 5, seed는 2003로 설정해 다섯 번의 훈련 folds에서 평균 AUC는 0.9468이 나왔다.

XGBoost모델의 성능을 평가하기 위해 ROC곡선과 혼동형렬을 시각화하는 과정을 수행하자.
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc, confusion_matrix
import seaborn as sns
plt.figure(figsize=(14, 6))
# ROC
plt.subplot(1, 2, 1)
for oof in xgb_oof:
fpr, tpr, _ = roc_curve(oof[:, 2], oof[:, 1])
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, label=f'ROC curve (area = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
# confusion matrix
plt.subplot(1, 2, 2)
# 혼동 행렬(Confusion Matrix)계산
# 확률 대신 예측 클래스 사용
# 예측 임계값으로 0.5 사용
predictions_class = [1 if pred > 0.5 else 0 for pred in predictions]
cm = confusion_matrix(df_woe['target'], predictions_class)
sns.heatmap(cm, annot=True, fmt='d')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.tight_layout()
plt.show()
- ROC 곡선 : 첫 번째 서브 플롯에서는 교차 검증 과정에서의 각 out-of-fold 예측에 대해 ROC 곡선을 그린다. ROC 곡선은 실제 양성 비율 대 거짓 양성 비율을 표시하여 모델의 이진 분류 가능성을 나타낸다. 곡선 아래의 면적(AUC)은 모델의 성능을 수치적으로 나타낸다. 이 면적이 1에 가까울수록 모델의 성능이 좋다는 것을 의미한다.
- 혼동행렬 : 두 번째 서브 플롯에서는 혼동 행렬을 시각화했다. 혼동 행렬은 모델이 실제 클래스와 얼마나 잘 일치하는지를 보여주는 행렬로, 실제 타겟값과 모델이 예측한 클래스를 비교하여 계산한다.
이제 머신러닝 모델로 나온 확률값을 신용 평가에 활용하기 위해 점수로 변환하자.
- 기본 설정 : 기본 점수는 650점으로 설정되어 있으며, PDO는 20점이다. 이는 확률의 로그 오즈가 두 배가 될 때 점수가 20점 증가한다는 것을 의미한다. *PDO : 신용점수가 얼마나 오르면 Odds(좋은 비율 / 나쁜 비율)가 2배로 늘어나는지를 수치화한 값
- 계수와 오프셋 계산 : 계수는 PDO를 로그 2의 값으로 나눈 것으로 계산되며, 이를 통해 확률의 변화에 따라 점수가 어떻게 조정되는지 결정한다. 오프셋은 기본 점수에서 로그 20을 계수로 곱한 값이 차감된 결과이다.
- 점수 계산 함수 : calculate_score 함수는 주어진 확률에 대해 해당 확률의 로그 오즈를 계산하고, 이를 활용해 신용 점수를 도출한다. 계산된 점수는 250점에서 1000점 사이로 제한한다.
- 점수 계산 및 반올림 : 입력된 확률에 대한 신용 점수를 계산하고, 결과 점수를 가장 가까운 정수로 반올림한다.
import numpy as np
import matplotlib.pyplot as plt
base_score = 650
PDO = 20
factor = PDO / np.log(2)
offset = base_score - (factor * np.log(20))
def calculate_score(probability, factor, offset):
odds = (probability / (1 - probability))
score = offset + (factor * np.log(odds))
return np.clip(score, 250, 1000) # Clip scores between 250 and 1000
scores = calculate_score(1 - predictions, factor, offset)
scores = np.round(scores)
plt.hist(scores, bins=20)
plt.title('Credit Score Distribution')
plt.xlabel('Score')
plt.ylabel('Frequency')
plt.show()
df_woe['probability'] = predictions
df_woe['credit_score'] = scores
samples = df_woe.sample(5, random_state=42)
samples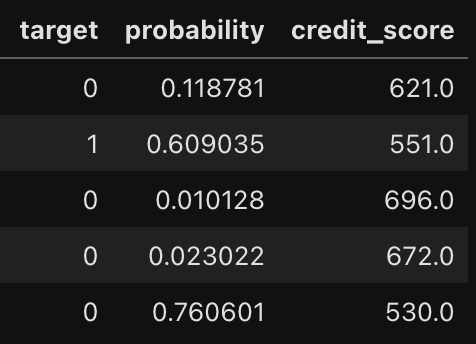
problbility는 위험고객임을 예측할 확률로 높을수록 위험고객일 확률이 높다. 따라서 credit_score가 낮아지고 실제 타겟값이 1이라면 예측에 성공한 것이다. 그러나 위의 샘플을 보면 예측에 실패한 케이스도 존재한다. 이는 모델의 개선이 더 필요하다는 점을 시사한다.
- probability가 높을수록 → credit_score는 낮아짐 → 위험고객(타겟 1)
- probability가 낮을수록 → credit_score는 높아짐 → 우량고객(타겟 0)
다음 코드는 새로운 inference 데이터가 들어왔을 때 원하는 형식으로 변환시켜 결과값을 예측하는 함수를 정의하고, 원하는 아웃풋인 확률과 스코어를 보여주도록 한다.
def predict_and_score(model, instance, factor, offset):
if len(instance.shape) == 1:
instance = instance.values.reshape(1, -1)
probability = model.predict_proba(instance)[:, 1]
score = calculate_score(1 - probability, factor, offset)
score = np.round(score)
return score[0]
inference = df_woe.drop(['target','probability','credit_score'], axis=1)
inference.sample(1)
sample = inference.sample(1)
score = predict_and_score(xgb_models[0], sample, factor, offset)
print("해당 고객의 신용 점수는 다음과 같습니다: ", score)
-->해당 고객의 신용 점수는 다음과 같습니다: 770.0
inference 데이터를 사용해 테스트까지 끝냈다면 배포하고자 하는 플랫폼에서 지원하는 형식에 맞춰 모델을 패키징해야 한다. 자주 사용하는 포맷으로는 PMML, ONNX 등이 있다.
'Data > Financial AI' 카테고리의 다른 글
| [금융 AI] AI 기반의 신용 리스크 모델링(5) - QnA (0) | 2025.04.10 |
|---|---|
| [금융 AI] AI 기반의 신용 리스크 모델링(4) - OptBinning 기반 신용 평가 모델 (0) | 2025.04.10 |
| [금융 AI] AI 기반의 신용 리스크 모델링(2) (0) | 2025.03.13 |
| [금융 AI] AI 기반의 신용 리스크 모델링(1) (1) | 2025.03.08 |
| [금융 AI] 금융 투자 영역에서의 AI(4) - 딥러닝을 이용한 투자 전략 (0) | 2025.03.02 |
