
짜리몽땅 매거진
[금융 AI] AI 기반의 신용 리스크 모델링(4) - OptBinning 기반 신용 평가 모델 본문
지난 머신러닝 기반 신용평가 모델에 이어 이번에는 OptBinning 라이브러리 기반의 신용 평가 모델을 개발해보자.
OptBinning 라이브러리는 변수의 binning(구간화)을 최적화해주는 파이썬 기반 오픈소스 라이브러리로, 주로 신용평가 모형 개발이나 머신러닝 feature engineering 과정에서 활용된다. 특히 연속형 변수나 범주형 변수를 적절하게 구간화해서 모델 성능 향상이나 해석력을 높일 때 유용하다.
지난 머신러닝 기반 신용평가 모델링의 전처리 및 시각화 과정까지는 동일하므로 그 다음 단계부터 살펴보자.
[금융 AI] AI 기반의 신용 리스크 모델링(3) - 머신러닝 기반 신용 평가 모델
머신러닝 기반의 신용 평가 모델링을 진행하고자 두 가지 데이터셋을 준비한다. 아메리칸 익스프레스 주최 파산 예측 경진대회 데이터셋(https://www.kaggle.com/competitions/amex-default-prediction/data)홈 크
zzarimongddang.tistory.com
pip install optbinningfrom optbinning import BinningProcess
라이브러리 설치 후 호출한다.
selection_criteria = {
"iv": {"min": 0.025, "max": 0.7, "strategy": "highest", "top": 20},
"quality_score": {"min": 0.01}
}
위 코드처럼 변수 선택 조건을 정해두면 해당 조건에 맞는 변수를 추출할 수 있다.
- min : IV값이 0.025 이상인 변수만 고려한다. 이는 변수가 최소한 일정 수준 이상의 예측력을 가져야 함을 의미한다.
- max : IV값이 0.7 이하인 변수만 고려한다. 너무 높은 IV값은 변수가 과도하게 타겟에 의존하고 있음을 나타낼 수 있으므로, 이를 통해 과적합을 방지한다.
- strategy : highest 전략을 사용하여 IV가 가장 높은 변수들을 우선적으로 선택한다.
- top : 상위 20개 변수만 선택한다. 이느 모델의 복잡성을 관리하고, 가장 유의미한 변수들만을 포함시키기 위함이다.
binning_process = BinningProcess(feature_list,
categorical_variables=cat_features,
selection_criteria=selection_criteria)
X = df[feature_list]
y = df['target']
binning_process.fit(X, y)
binning_process.information(print_level=2)
information 메서드는 구간화 작업에 대한 상세 정보를 출력한다. print_level은 출력할 정보의 상세 수준을 지정한다.
binning_process.summary()
summary()메서드는 binning_process 객체가 수행한 구간화 과정의 요약 정보를 제공한다. 변수이름, 구간 수, IV, WoE, 통계적 지표를 제공한다. 선택된 변수만 보고 싶다면 아래 코드를 참조해보자.
summary = binning_process.summary()
selected_summary = summary[summary["selected"] == True]\
selected_summary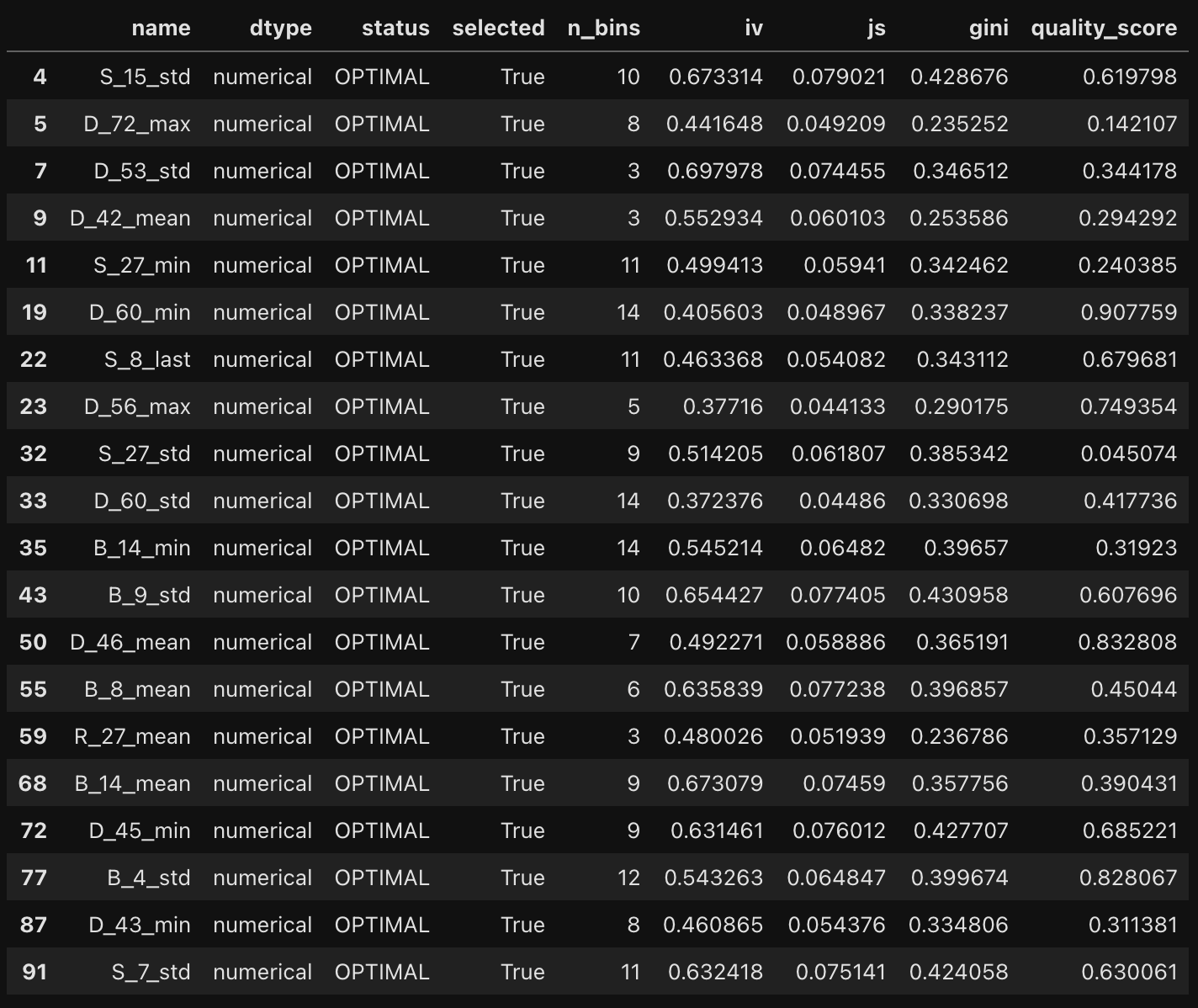
optb = binning_process.get_binned_variable("D_42_mean")
optb.binning_table.build()
build() 메서드는 구간화된 데이터에 대한 상세한 테이블을 구축한다. 이 테이블은 각 구간에 대한 정보, 예를 들어 구간의 경계, 구간 내의 관측치 수, 각 구간의 타깃 변수에 대한 비율, WoE, IV값 등을 포함할 수 있다.
optb.binning_table.plot(metric="event_rate")
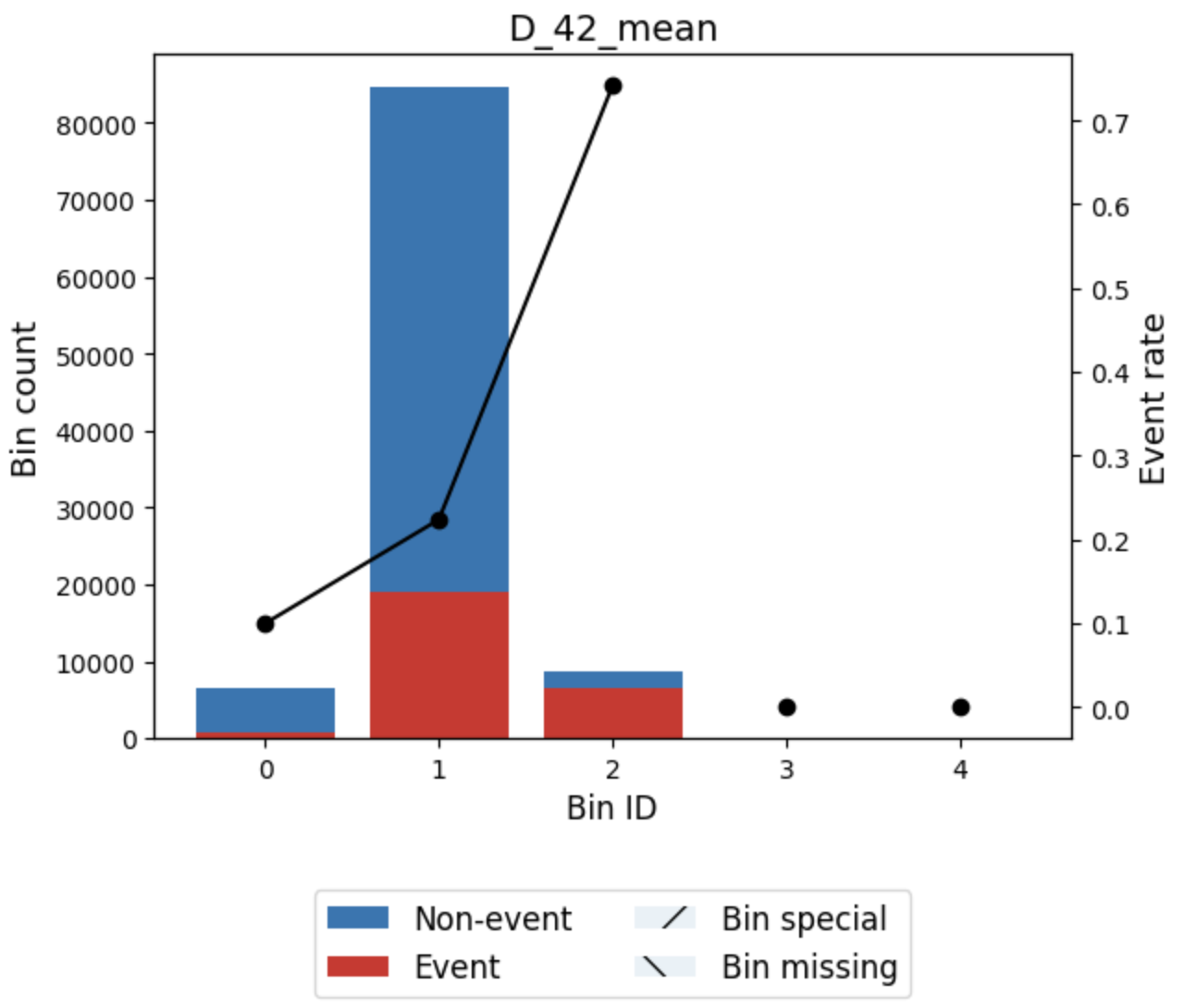
구간화 그래프를 살펴보면 D_42_mean 변수같은 경우 2구간에서 불량율이 매우 높게 나타난다. 이벤트 발생 확률 또한 단조 증가함을 알 수 있다. 일반적으로 구간화는 이벤트 발생 확률이 단조 증가하면 좋다고 판단한다.
binning_process.get_support(names=True)
--> array(['S_15_std', 'D_72_max', 'D_53_std', 'D_42_mean', 'S_27_min',
'D_60_min', 'S_8_last', 'D_56_max', 'S_27_std', 'D_60_std',
'B_14_min', 'B_9_std', 'D_46_mean', 'B_8_mean', 'R_27_mean',
'B_14_mean', 'D_45_min', 'B_4_std', 'D_43_min', 'S_7_std'],
dtype='<U13')
이제 어떤 변수들이 선택되었는지 살펴보자.
X_transform = binning_process.transform(X, metric="woe")
이전 머신러닝 기반 신용 평가 모델링에서는 직접 IV와 WoE 함수를 만들어 데이터를 변환했다. 하지만 이 작업은 OptBinning 라이브러리를 사용하면 한 줄의 코드로 실행 가능하다. 이제 변환된 WoE값을 사용해 모델링을 진행하자.
from sklearn.linear_model import LogisticRegression
from optbinning import Scorecard
from optbinning.scorecard import Counterfactual
binning_process = BinningProcess(feature_list,
categorical_variables=cat_features,
selection_criteria=selection_criteria)
estimator = LogisticRegression(solver="lbfgs")
scorecard = Scorecard(binning_process=binning_process,
estimator=estimator, scaling_method="min_max",
scaling_method_params={"min": 300, "max": 850})
scorecard.fit(X, y)
scorecard.table(style="summary")
scorecard.table(style="detailed")
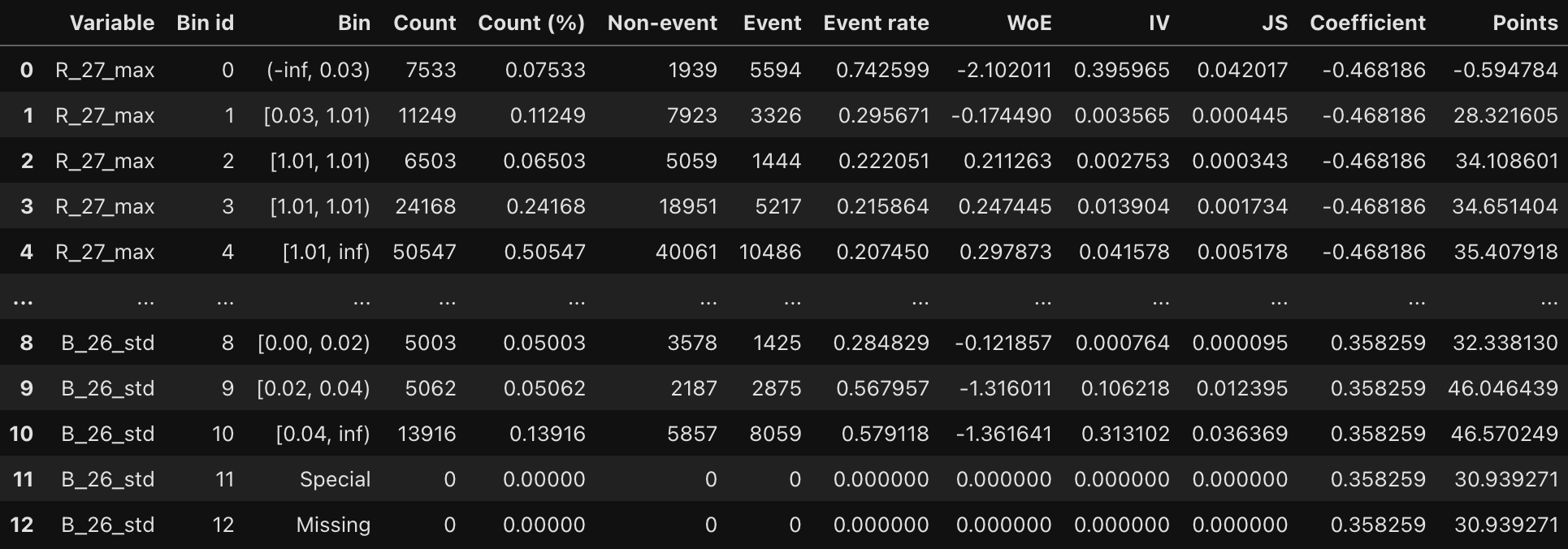
다음은 table() 메서드의 style 파라미터에 summary를 적용할 때 나오는 테이블 예시다. 파라미터를 detailed로 변경하면 더 많은 정보가 출력된다.
y_pred = scorecard.predict_proba(X)[:, 1]
from optbinning.scorecard import plot_auc_roc, plot_cap, plot_ks
plot_auc_roc(y, y_pred)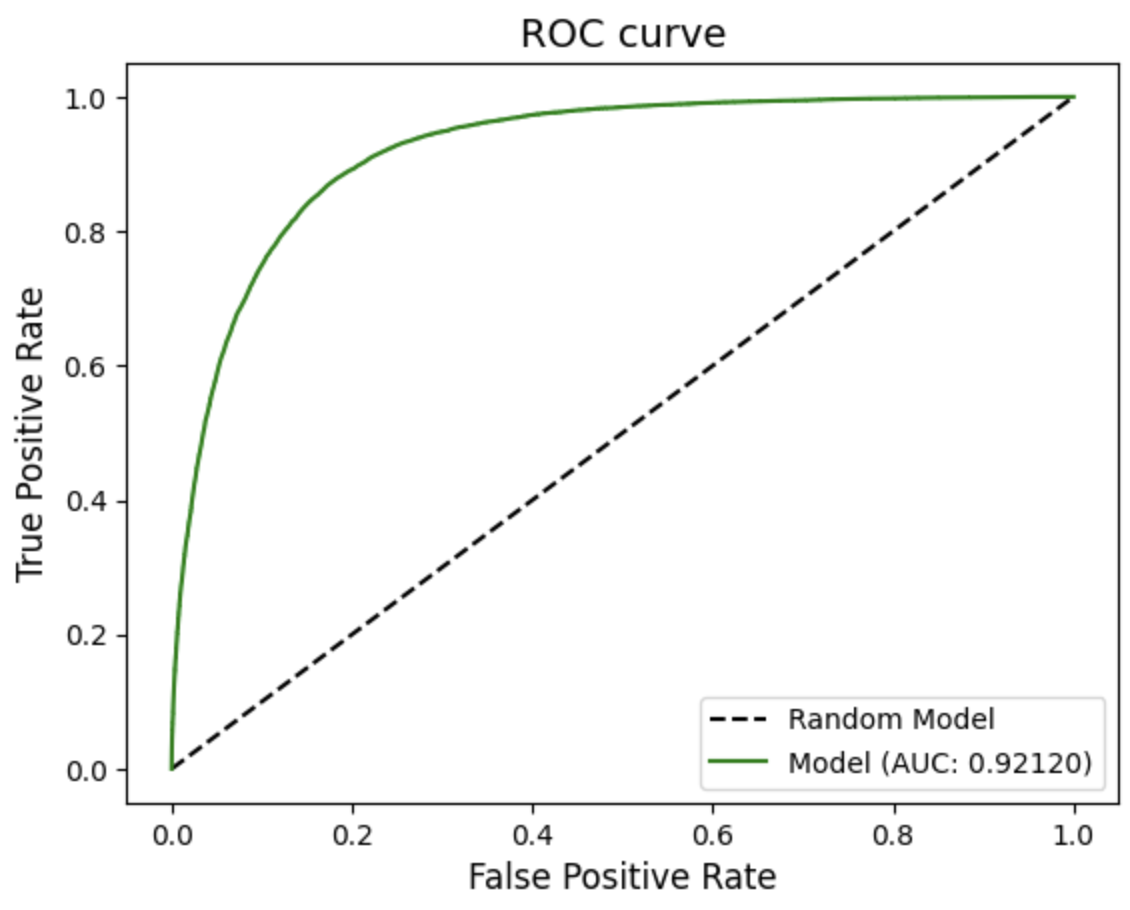
단순한 모델을 사용하니 AUC가 이전 머신러닝 기반 모델보다 떨어진 것을 확인할 수 있다. 하지만 데이터 전처리가 잘 된 편이라 점수가 아주 낮진 않다.
plot_ks(y, y_pred)
지난 포스팅에서 설명한 K-S 통계량도 간단한 함수로 계산하고 시각화한다.
OptBinning 라이브러리를 사용한 모델 모니터링
모델을 운영 환경에 배포한 후, 그 성능이 시간이 지남에 따라 어떻게 변화하는지 지속적으로 관찰하는 것은 매우 중요하다. 모델의 예측력이 예상 밖으로 변하는 현상을 모델 드리프트라고 한다. 모델 드리프트를 식별하고 관리하는 것은 모델의 신뢰성을 유지하고 장기적인 성과를 보장하는 데 필수다.
OptBinning 라이브러리는 이런 모니터링 작업을 용이하게 하는 다양한 기능을 제공한다. 그중에서도 모델이 생성된 시점과 현재 또는 특정 시점의 데이터 분포가 얼마나 변화했는지를 측정하는 지표인 PSI를 계산함으로써, 모델 입력 변수의 분포가 시간에 따라 어떻게 변하는지 정량적으로 평가할 수 있다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=42)
scorecard.fit(X_train, y_train)from optbinning.scorecard import ScorecardMonitoring
monitoring = ScorecardMonitoring(scorecard=scorecard, psi_method="cart",
psi_n_bins=10, verbose=True)
monitoring.fit(X_test, y_test, X_train, y_train)
라이브러리의 ScorecardMonitoring 클래스를 사용하여 스코어카드 모델의 모니터링을 설정한다. psi_method로 cart를 설정했다는 것은 PSI를 계산할 때 CART 알고리즘을 사용하겠다는 것인데, CART 알고리즘은 데이터를 구분하는 결정 트리를 생성하여 각 구간의 PSI를 계산한다.
monitoring.psi_table()
monitoring.psi_plot()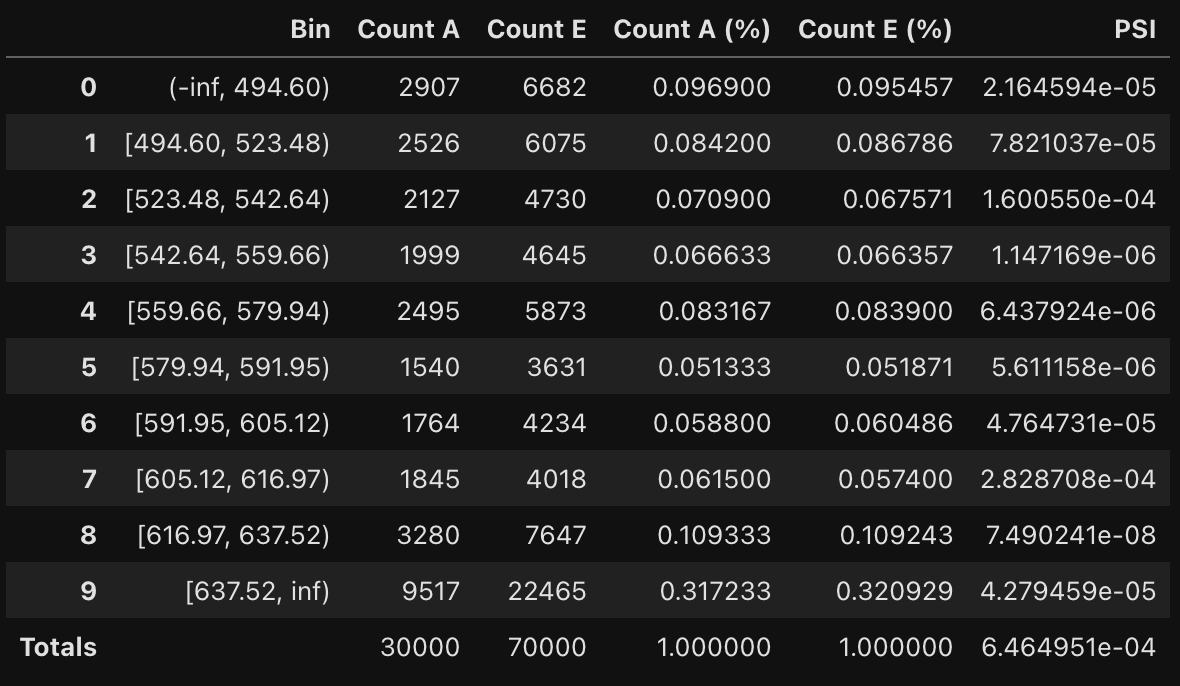
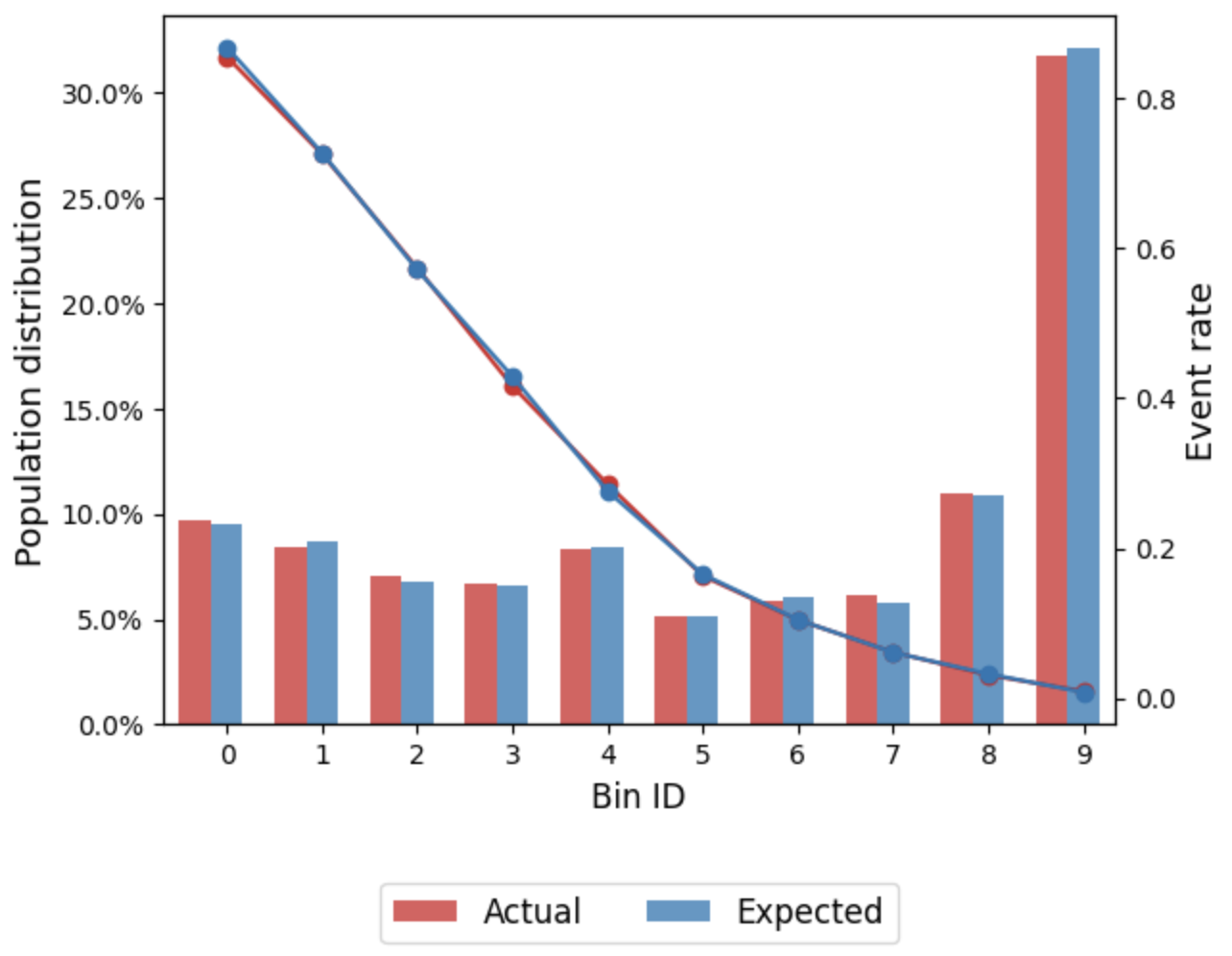
PSI값이 포함된 테이블과 그래프를 생성한다. 굉장히 안정적이다.
monitoring.tests_table()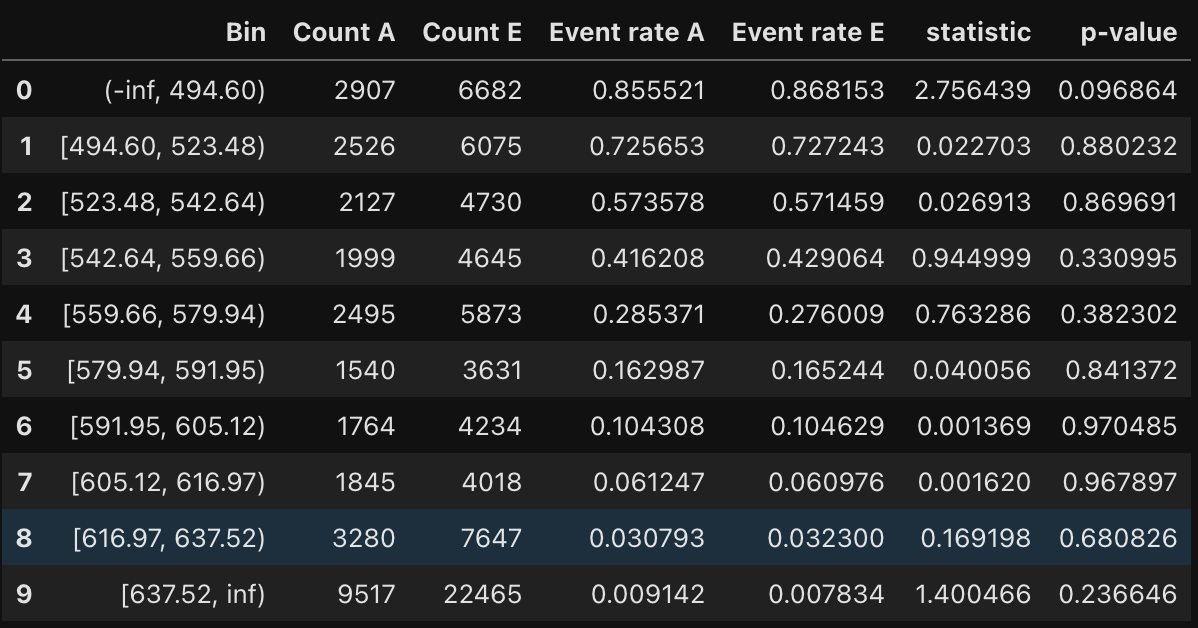
이 통계적 검정은 이벤트 비율(카이제곱 검정-이진타겟) 또는 평균(t검정-연속타겟)이 유의하게 다른지 여부를 결정하기 위해 수행된다. 귀무가설은 실제값이 예상값과 동일하다는 것이다.
monitoring.system_stability_report()
-->
-----------------------------------
Monitoring: System Stability Report
-----------------------------------
Population Stability Index (PSI)
PSI total: 0.0006 (No significant change)
PSI bin Count Count (%)
[0.00, 0.10) 10 1.0
[0.10, 0.25) 0 0.0
[0.25, Inf+) 0 0.0
Significance tests (H0: actual == expected)
p-value bin Count Count (%)
[0.00, 0.05) 0 0.0
[0.05, 0.10) 1 0.1
[0.10, 0.50) 3 0.3
[0.50, 1.00) 6 0.6
Target analysis
Metric Actual Actual (%) Expected Expected (%)
Number of records 30000 - 70000 -
Event records 7820 0.260667 18247 0.260671
Non-event records 22180 0.739333 51753 0.739329
Performance metrics
Metric Actual Expected Diff A - E
True positive rate 0.672251 0.673042 -0.000792
True negative rate 0.921641 0.923135 -0.001494
False positive rate 0.078359 0.076865 0.001494
False negative rate 0.327749 0.326958 0.000792
Balanced accuracy 0.796946 0.798089 -0.001143
Discriminant power 1.755011 1.768498 -0.013486
Gini 0.830341 0.835401 -0.005060
시스템 리포트를 통해 확인할 수도 있다.
'Data > Financial AI' 카테고리의 다른 글
| [금융 AI] AI 기반 금융 사기 탐지(1) - 금융 사기 거래 탐지의 중요성과 AI (0) | 2025.04.14 |
|---|---|
| [금융 AI] AI 기반의 신용 리스크 모델링(5) - QnA (0) | 2025.04.10 |
| [금융 AI] AI 기반의 신용 리스크 모델링(3) - 머신러닝 기반 신용 평가 모델 (0) | 2025.03.29 |
| [금융 AI] AI 기반의 신용 리스크 모델링(2) (0) | 2025.03.13 |
| [금융 AI] AI 기반의 신용 리스크 모델링(1) (1) | 2025.03.08 |
