
짜리몽땅 매거진
[ML] 머신러닝에서의 거리기반 측정 본문
KNN 알고리즘과 K-means 클러스터링과 같은 머신러닝의 기초적인 모델들은 모두 거리기반 측정을 바탕으로 시작한다.
KNN 알고리즘의 경우 가까운 속성에 따라 분류한다고 했는데 '가깝다'는 것에는 기준이 필요하다. 나중에 KNN 알고리즘에 대해 자세히 다루겠지만, KNN 알고리즘은 거리기반 분류분석 모델로 거리를 기반으로 분류하는 알고리즘이며 따라서 상대적으로 거리가 더 짧은 이웃이 더 가까운 이웃으로 취급된다. 즉, KNN 알고리즘은 어떤 새로운 데이터로부터 거리가 가까운 K개의 다른 데이터의 레이블(속성)을 참고하여 K개의 데이터 중 가장 빈도 수가 높게 나온 데이터의 레이블로 분류하는 알고리즘이다.
K-means 알고리즘에서 K는 묶을 군집의 개수를 의미하고 means는 평균을 의미한다. 단어 그대로의 의미를 해석해보면 각 군집의 평균을 활용하여 K개의 군집으로 묶는다는 의미다. 여기서 평균이란 각 클러스터의 중심과 데이터들의 평균 거리를 의미하는데 KNN 알고리즘과 동일하게 거리 기반으로 군집화가 진행된다.
numpy와 실제 함수를 만들어서 거리를 측정하는 것이 가능하지만, scipy 라이브러리에서 제공하는 distance 모듈을 가지고 간단히 거리를 측정하는 실습을 진행해보았다.
'Starbucks_Seoul.csv' 샘플 데이터셋을 활용했고, 데이터프레임은 아래와 같다.

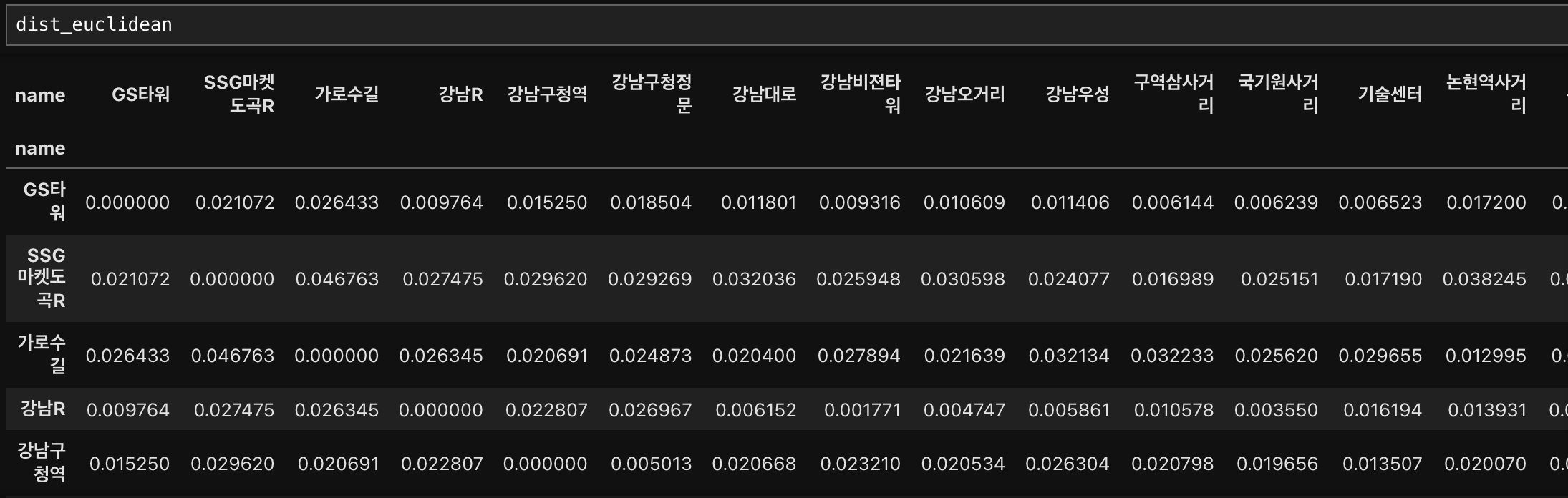
1. 유클리드 거리

(입력)
# 유클리디안 거리 잡기
dist_euclidean = distance.cdist(df1[['latitude','longitude']],
df1[['latitude','longitude']], metric = 'euclidean')
#컬럼과 인덱스를 설정해서 거리를 쉽게 볼 수 있게 dataframe으로 만들기
dist_euclidean = pd.DataFrame(data=dist_euclidean, columns = df1['name'])
dist_euclidean.set_index(df1['name'], inplace=True)
(출력)
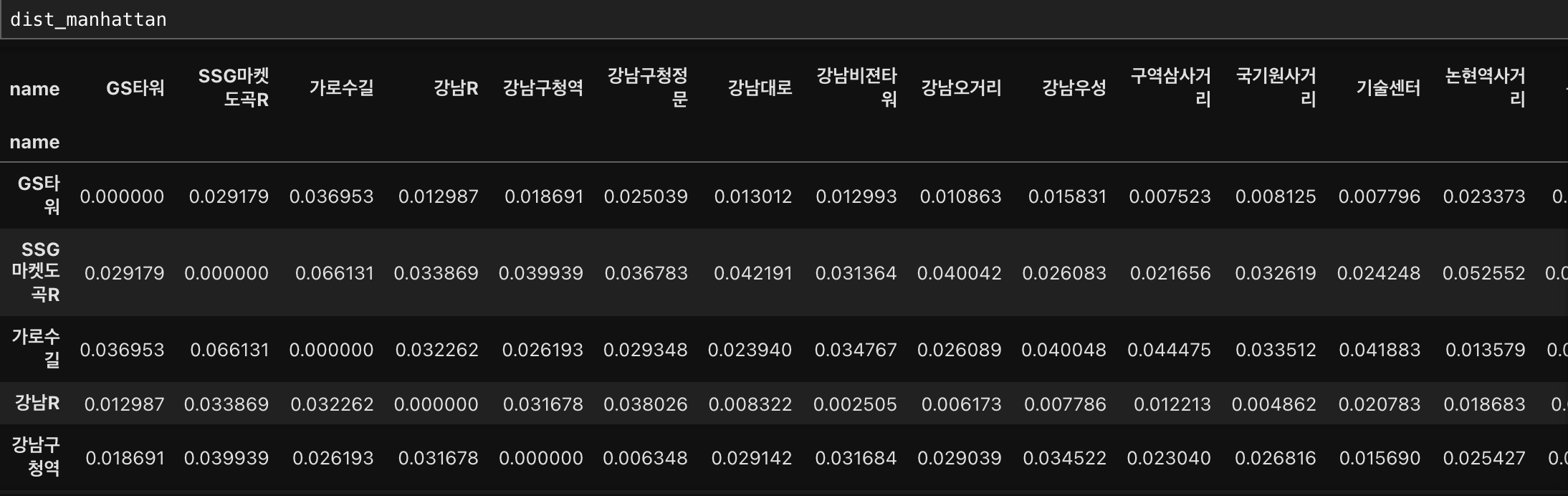
2. 맨해튼 거리
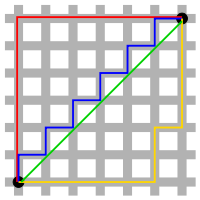
초록색 선을 제외한 선들이 맨해튼 거리이다.
(입력)
# 맨하튼 거리 잡기
dist_manhattan = distance.cdist(df1[['latitude','longitude']],
df1[['latitude','longitude']], metric = 'cityblock')
#컬럼과 인덱스를 설정해서 거리를 쉽게 볼 수 있게 dataframe으로 만들기
dist_manhattan = pd.DataFrame(data=dist_manhattan, columns = df1['name'])
dist_manhattan.set_index(df1['name'], inplace=True)
(출력)
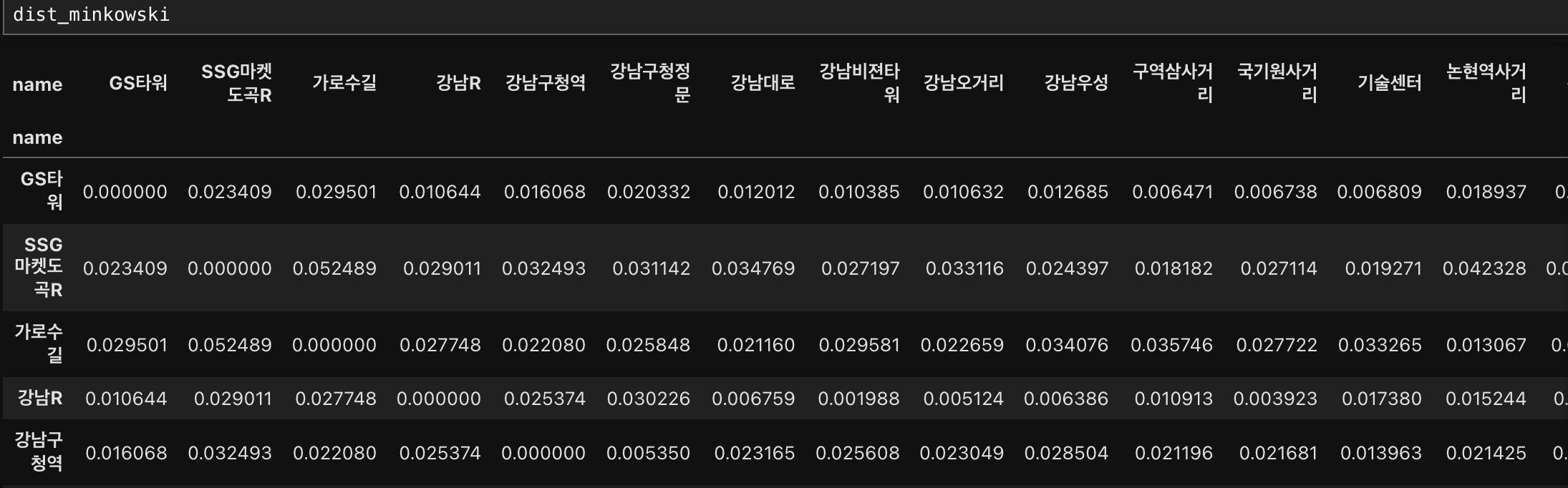
3. 민코프스키 거리
(입력)
# 민코프스키 거리 잡기
dist_minkowski = distance.cdist(df1[['latitude','longitude']],
df1[['latitude','longitude']], metric = 'minkowski',p = 1.5)
#컬럼과 인덱스를 설정해서 거리를 쉽게 볼 수 있게 dataframe으로 만들기
dist_minkowski = pd.DataFrame(data=dist_minkowski, columns = df1['name'])
dist_minkowski .set_index(df1['name'], inplace=True)
(출력)
4. 체비쇼프 거리
(입력)
# 체비쇼프 거리 잡기
dist_chebyshev = distance.cdist(df1[['latitude','longitude']],
df1[['latitude','longitude']], metric = 'chebyshev')
#컬럼과 인덱스를 설정해서 거리를 쉽게 볼 수 있게 dataframe으로 만들기
dist_chebyshev = pd.DataFrame(data=dist_chebyshev, columns = df1['name'])
dist_chebyshev.set_index(df1['name'], inplace=True)
(출력)

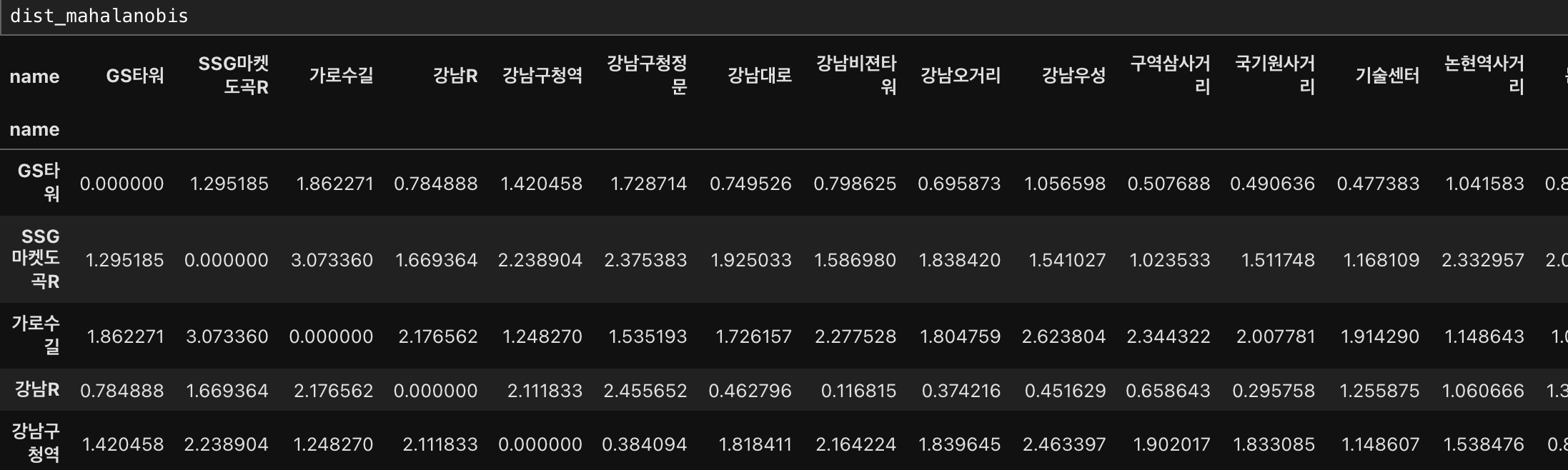
5. 마할라노비스 거리
(입력)
# 마할라노비스 거리 잡기
dist_mahalanobis = distance.cdist(df1[['latitude','longitude']],
df1[['latitude','longitude']], metric = 'mahalanobis')
#컬럼과 인덱스를 설정해서 거리를 쉽게 볼 수 있게 dataframe으로 만들기
dist_mahalanobis = pd.DataFrame(data=dist_mahalanobis, columns = df1['name'])
dist_mahalanobis.set_index(df1['name'], inplace=True)
(출력)
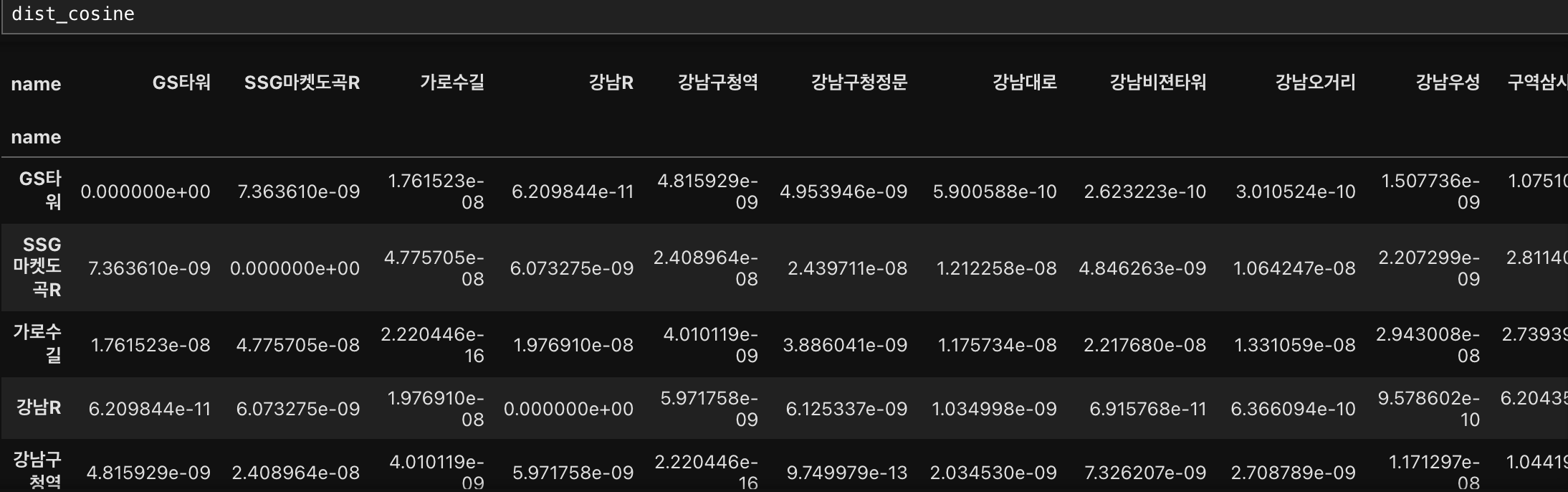
6. 코사인 거리
(입력)
# 코사인 거리 잡기
dist_cosine = distance.cdist(df1[['latitude','longitude']],
df1[['latitude','longitude']], metric = 'cosine')
#컬럼과 인덱스를 설정해서 거리를 쉽게 볼 수 있게 dataframe으로 만들기
dist_cosine = pd.DataFrame(data=dist_cosine, columns = df1['name'])
dist_cosine.set_index(df1['name'], inplace=True)
(출력)
'Data > Machine Learning' 카테고리의 다른 글
| [ML] Kmeans 알고리즘 + DBSCAN (0) | 2024.06.23 |
|---|---|
| [ML] KNN 알고리즘 (0) | 2024.06.22 |
| [ML] Feature Selection (0) | 2024.06.22 |
| [ML] 데이터 스케일링 (0) | 2024.06.05 |
| [ML] train_test_validation 데이터와 교차검증(CV) (0) | 2024.05.14 |



