
짜리몽땅 매거진
[금융 AI] AI 기반 금융 사기 탐지(2) - SMOTE & XGBoost 기반 신용카드 사기 거래 탐지 모델 본문
[금융 AI] AI 기반 금융 사기 탐지(2) - SMOTE & XGBoost 기반 신용카드 사기 거래 탐지 모델
쿡국 2025. 4. 17. 08:14본격적으로 사기 거래 탐지를 위한 모델링을 해보자. 첫 번째로 살펴볼 방법은 머신러닝 지도학습법을 활용한 모델 개발이다. 이 접근법은 레이블링 과정을 거쳐 사기로 분류된 거래 데이터를 사용한다.
이번 실습에서 사용할 데이터셋은 다음과 같다.
Credit Card Fraud Detection
Anonymized credit card transactions labeled as fraudulent or genuine
www.kaggle.com
사기 거래는 전체 거래에서 차지하는 비율이 매우 낮아, 이러한 불균형한 데이터 상태에서 효과적인 모델링을 위해서는 특별한 접근 방법이 필요하다. 이를 위해 트리 기반 모델을 활용할 예정이며, 데이터 불균형 문제를 해결하기 위해 SMOTE 기법을 사용한다. SMOTE는 소수 클래스의 샘플을 합성하여 모델 학습 시 소수 클래스의 영향력을 강화하는 기법이다. 지난 데이터 샘플링 관련 글을 참고하길 바란다.
[ML] 데이터 샘플링
모델링을 할 때 데이터 '샘플링'을 해야한다는 말을 들어본 적 있을 것이다. 그렇다면 왜 샘플링을 해야할까? 통상적으로 예측하는 경우는 대부분 소수의 경우를 예측하는 경우가 많다. 예를 들
zzarimongddang.tistory.com
그렇다면 본격적으로 실습을 시작해보자.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, StratifiedKFold, GridSearchCV
from sklearn.metrics import roc_auc_score
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from imblearn.over_sampling import SMOTE
from xgboost import XGBClassifier
import matplotlib.pyplot as plt
import plotly.express as px
import seaborn as sns
from imblearn.pipeline import make_pipeline as imbalanced_make_pipeline
data = pd.read_csv('creditcard.csv')
X = data.drop('Class', axis=1)
y = data['Class']
필요한 라이브러리와 데이터를 로드한 후, Class열을 제외한 모든 열을 피처로 분리한다. Class열은 각 거래가 사기인지 아닌지를 나타내는 레이블이다.
from plotly.offline import init_notebook_mode, iplot
init_notebook_mode(connected=True)
fig2 = px.pie(data, names='Class',
height=400, width=600,
hole=0.7,
title='Fraud Class Overview',
color_discrete_sequence=['#4c78a8', '#72b7b2'])
fig2.update_traces(hovertemplate=None, textposition='outside', textinfo='percent+label', rotation=0)
fig2.update_layout(margin=dict(t=100, b=30, l=0, r=0), showlegend=False,
plot_bgcolor='#fafafa', paper_bgcolor='#fafafa',
title_font=dict(size=20, color='#555', family="Lato, sans-serif"),
font=dict(size=14, color='#8a8d93'),
hoverlabel=dict(bgcolor="#444", font_size=13, font_family="Lato, sans-serif"))
fig2.show()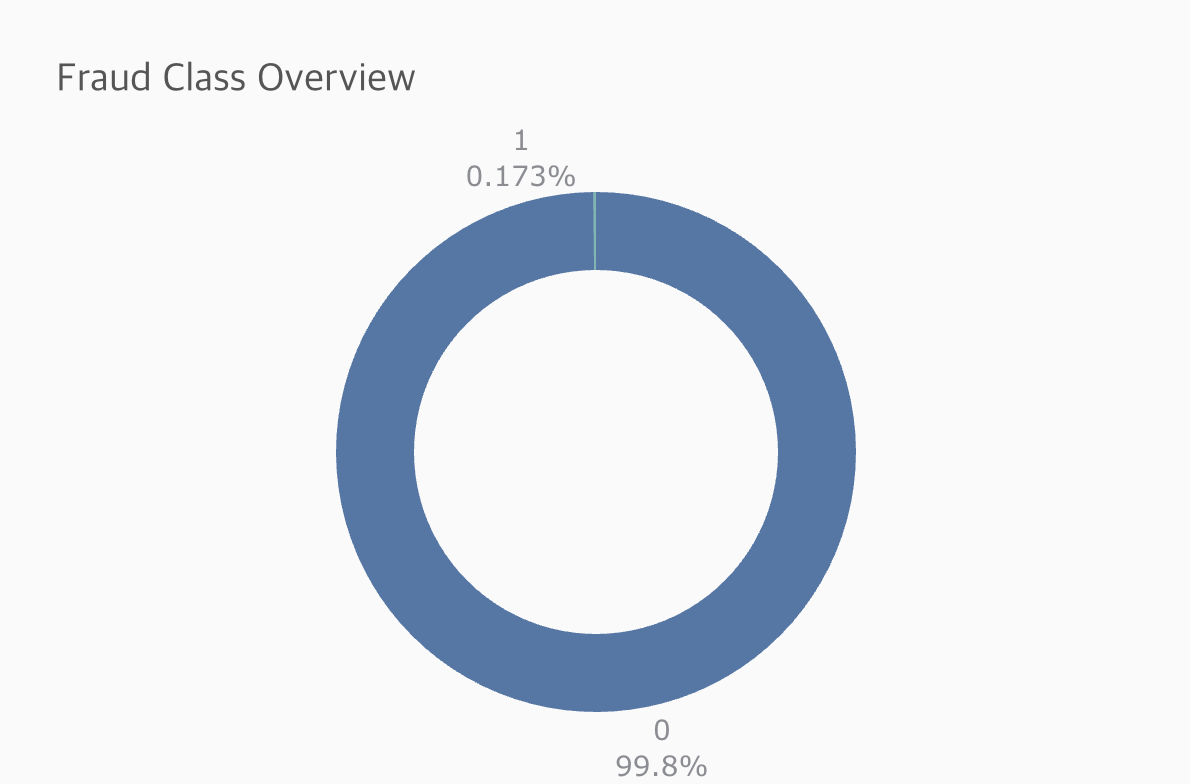
이후 plotly 사용해 신용카드 거래 데이터에서 사기 거래와 정상 거래의 비율을 시각화 한다. 이제 요약 테이블 함수를 만들어 간단한 EDA를 해본다.
# summary table function
def summary(df):
print(f'data shape: {df.shape}')
summ = pd.DataFrame(df.dtypes, columns=['data type'])
summ['#missing'] = df.isnull().sum().values * 100
summ['%missing'] = df.isnull().sum().values / len(df)
summ['#unique'] = df.nunique().values
desc = pd.DataFrame(df.describe(include='all').transpose())
summ['min'] = desc['min'].values
summ['max'] = desc['max'].values
summ['first value'] = df.loc[0].values
summ['second value'] = df.loc[1].values
summ['third value'] = df.loc[2].values
return summ
summary(data)
각 열별로 어떤 데이터 타입으로 저장되었는지, 결측치는 얼마나 있는지, 최소값 및 최대값은 얼마인지 더욱 구체적으로 파악할 수 있다.
# 학습/테스트 데이터 분리 (3:7 비율)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 스케일링
scaler = StandardScaler()
# 스케일링 적용
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# StratifiedKFold 객체 생성
kf = StratifiedKFold(n_splits=5, random_state=42, shuffle=True)
# XGBoost GPU 설정
gpu_params = {'tree_method': 'gpu_hist'}
# SMOTE 및 XGBoost 파이프라인 설정
pipeline = imbalanced_make_pipeline(SMOTE(random_state=42), XGBClassifier(n_jobs=-1,
random_state=42,
**gpu_params))
본격적으로 모델링을 위한 준비를 시작한다. 데이터를 학습용과 테스트용으로 분리하고, 스케일링 진행 및 교차 검증을 준비한다. StratifiedKFold 객체를 통해 클래스 비율을 유지하면서 데이터를 다섯 개의 폴드로 나눈다. 이는 모델의 성능을 공정하게 평가하고, 과적합을 방지한다. XGBoost 모델의 설정에는 GPU를 사용하는 gpu_hist 메서드가 포함된다. 이는 계산 속도를 높이기 위함이다. 마지막으로 imbalanced_make_pipeline을 사용하여 SMOTE기법과 XGBoost 분류기를 결합한 파이프라인을 생성한다.
# 그리드 설정
param_grid = {
'smote__sampling_strategy': [0.1, 0.25, 0.5, 0.75, 1.0],
'xgbclassifier__max_depth': [3, 4, 5, 6],
'xgbclassifier__subsample': [0.6, 0.8, 1.0]
}
# GridSearchCV 설정
grid = GridSearchCV(pipeline, param_grid=param_grid, cv=kf, scoring='roc_auc',
return_train_score=True)
# 그리드서치 실행
grid.fit(X_train, y_train)
# 최적의 파라미터 출력
print('Best parameters:', grid.best_params_)
이제 그리드서치를 통해 최적의 하이퍼파라미터를 출력하여 최적의 모델에 저장하는 과정을 거친다.
# 최적의 모델 저장
best_model = grid.best_estimator_
# 그리드서치 결과를 데이터프레임으로 변환
cv_results = pd.DataFrame(grid.cv_results_)
# 훈련 세트의 성능과 교차검증 세트의 성능을 비교
cv_results[['param_smote__sampling_strategy', 'param_xgbclassifier__max_depth',
'param_xgbclassifier__subsample', 'mean_train_score', 'mean_test_score']]
위 코드는 그리드 서치의 결과를 데이터프레임 형태로 변환하고, 훈련 데이터셋과 교차 검증 데이터셋에서의 성능을 비교하는 과정이다. cv_results_ 속성을 활용해 그리드 서치의 모든 결과를 데이터프레임으로 변환하고, 필요한 열만 선택하여 SMOTE의 샘플링 전략, XGBoost 분류기의 최대 깊이와 하위 샘플 비율, 각 조합에 대한 평균 훈련 점수와 테스트 점수를 표시한다. 이를 통해 모델의 과적합 여부와 각 파라미터 조합의 효율성을 평가할 수 있다.

# 테스트 세트에 최적의 모델 적용 및 AUC-ROC 계산
y_test_pred = best_model.predict_proba(X_test)[:,1]
print('Final ROC AUC Score:', roc_auc_score(y_test, y_test_pred))
--> Final ROC AUC Score: 0.9901727773529376
마지막으로 테스트셋에서 모델의 성능을 확인해본다.
XGBoost와 같은 결정 트리 기반의 모델은 훈련 데이터에 대해 완벽하게 학습(overfitting)할 수 있기 때문에 훈련 점수가 1이 나올 수 있다. 이것은 모델이 훈련 데이터에 과적합될 가능성이 있음을 나타낸다. 이런 현상은 특히 불균형 데이터셋에서 자주 발생하는데, SMOTE를 사용하여 소수 클래스를 오버샘플링하면, 새롭게 생성된 샘플은 원래 샘플과 매우 유사하기 때문에 모델이 쉽게 학습할 수 있다. 이로 인해 훈련 세트의 성능은 매우 높지만, 검증 세트에서의 성능은 상대적으로 낮아질 수 있다. 하지만, 교차 검증 점수가 0.96~0.98 사이로 나타났다면, 이는 모델이 검증 세트에서도 잘 일반화되고 있다는 좋은 신호다. 물론, 이 점수는 테스트 세트에서도 유지될지 확인해야 한다. 교차 검증은 모델 성능의 안정성을 평가하는 좋은 방법이지만, 최종 테스트 세트에서의 성능이 가장 중요하다.
'Data > Financial AI' 카테고리의 다른 글
| [금융 AI] AI 기반 금융 사기 탐지(4) - AutoEncoder 기반 신용카드 사기 거래 탐지 모델 (0) | 2025.05.01 |
|---|---|
| [금융 AI] AI 기반 금융 사기 탐지(3) - Isolation Forest 기반 신용카드 사기 거래 탐지 모델 (1) | 2025.04.19 |
| [금융 AI] AI 기반 금융 사기 탐지(1) - 금융 사기 거래 탐지의 중요성과 AI (0) | 2025.04.14 |
| [금융 AI] AI 기반의 신용 리스크 모델링(5) - QnA (0) | 2025.04.10 |
| [금융 AI] AI 기반의 신용 리스크 모델링(4) - OptBinning 기반 신용 평가 모델 (0) | 2025.04.10 |
