
짜리몽땅 매거진
[Python] 콘텐츠 기반 추천 시스템 본문
추천 시스템의 종류

콘텐츠 기반 필터링(Content-based Filtering)
- 콘텐츠 자체의 특성과 사용자의 이전 행동 기록을 기반으로 사용자에게 추천함
- 예를 들어, 사용자가 영화 '캡틴 마블'을 재밌게 보았다면 '캡틴 마블'에 대한 분석을 바탕으로 성격이 유사한 영화 '블랙 위도우'를 추천함
장점
- 개인화된 추천: 사용자의 개별적인 취향을 반영 가능함
- 새로운 아이템 대응: 아이템 자체의 특성을 기반으로 하기 때문에 새로운 아이템에도 상대적으로 잘 대응 가능함
- 콜드 스타트에 강함: 사용자의 이력이 없는 초기 상태에도 추천 가능함
단점
- 제한된 다양성: 각 콘텐츠에서 얻을 수 있는 정보가 달라 다양한 형식의 항목 추천이 어려움
협업 필터링(Collaborative Filtering)
- 어떤 아이템에 대해서 비슷한 취향을 가진 사람들이 다른 아이템에 대해서도 비슷한 취향을 가지고 있을 것이라고 가정하고 추천을 하는 알고리즘
- 추천의 대상이 되는 사람과 취향이 비슷한 사람들, 즉 neighbor을 찾아 이 사람들이 공통적으로 좋아하는 제품 또는 서비스를 추천 대상인에게 추천하는 것
장점
- 알고리즘의 결과가 직관적
- domain knowledge free: 항목의 구체적인 내용 분석이 필요하지 않음
단점
- 콜드 스타트: 신규 사용자에 대해서 정보 데이터가 없어 추천 어려움
- 롱테일: 사용자들이 소수의 인기 있는 항목에만 관심을 보여서 관심이 저조한 항목은 추천되지 못함 → 비대칭적 쏠림 현상
- 계산 효율의 저하: 사용자들의 수가 많아 데이터가 많이 쌓이게 되면, 정확도는 증가하지만 시간이 오래 걸려 효율성은 하락함

하이브리드 필터링 (Hybrid Filtering)
- 2가지 이상 다양한 종류의 추천 시스템 알고리즘을 조합하는 방법
- 다양한 알고리즘들의 단점은 보완하고 장점은 결합함
위의 추천시스템 개념을 바탕으로 콘텐츠 필터링 기반 관광지 추천 시스템 알고리즘을 실습해보자.
0. 라이브러리 호출 및 데이터 불러오기
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
df=pd.read_csv('천안시 관광지.csv')
df
1. Count 벡터화 및 코사인 유사도 계산
df['내용'] = df['관광지명'] + ' ' + df['중분류 카테고리'] + ' ' + df['소분류 카테고리']
# count 벡터화
count_vectorizer = CountVectorizer()
count_matrix = count_vectorizer.fit_transform(df['내용'])
# 코사인 유사도 계산
cosine_sim = cosine_similarity(count_matrix, count_matrix)
# 유사도 3위까지
def get_recommendations(idx, sim_matrix):
sim_scores = list(enumerate(sim_matrix[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores = sim_scores[1:4] # 자기 자신을 제외하고 상위 3개
return [i[0] for i in sim_scores]
df['유사 관광지'] = df.index.map(lambda x: get_recommendations(x, cosine_sim))
df['유사 관광지명'] = df['유사 관광지'].apply(lambda x: [df.loc[i, '관광지명'] for i in x])
df
관광지명, 중분류 카테고리, 소분류 카테고리 변수를 기반으로 A관광지와 유사한 B,C,D관광지(유사도 3순위까지)를 출력하는 코드이다.
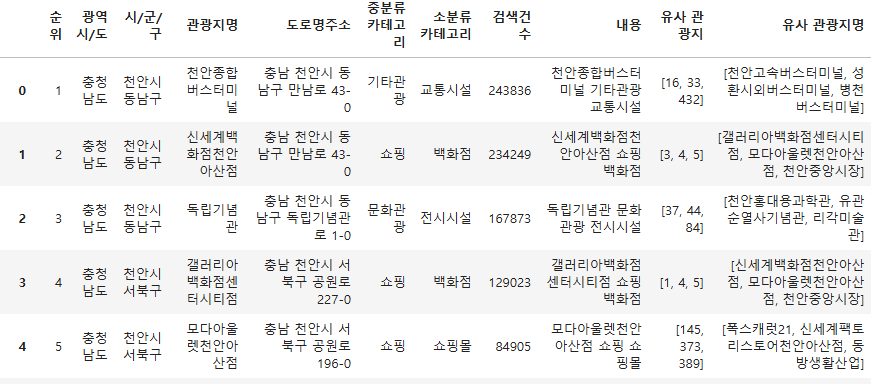
다음 결과 데이터와 같이 '유사 관광지명' 칼럼에 유사도 3위까지의 리스트 값이 추가된 것을 볼 수 있다.
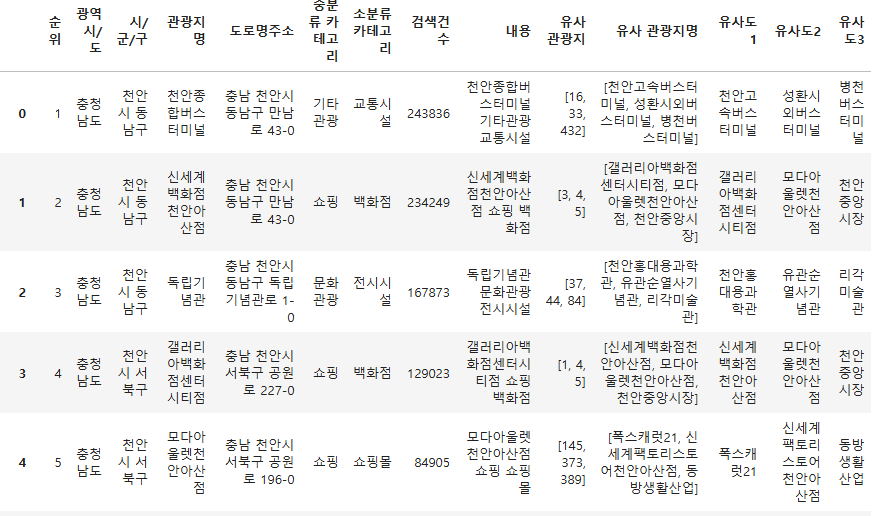
df[['유사도1', '유사도2', '유사도3']] = pd.DataFrame(df['유사 관광지명'].tolist(), index=df.index)
df
위 코드를 통해 각 리스트에 포함된 3개의 관광지를 각각의 칼럼으로 구분지을 수 있다.
'Data > Python' 카테고리의 다른 글
| [Python] 상관분석하고 네트워크 차트로 시각화하기 (0) | 2025.01.04 |
|---|---|
| [Python] Featuretools로 고객데이터 분석하기 (0) | 2024.10.28 |
| [Python] 상관분석 (0) | 2024.07.01 |
| [Python] 네이버 뉴스기사 크롤링하고 감성분석하기 (1) | 2024.06.25 |
| [Python] 데이터에서의 Outlier 처리 (0) | 2024.04.22 |
'Data/Python' Related Articles
more



