
짜리몽땅 매거진
[Python] 상관분석 본문
'제주도 신재생 에너지 활용을 통한 전력 비용 절감 및 탄소 배출 감소 분석'을 주제로 날짜별 기상데이터, 태양광 발전량 데이터, 풍력 발전량 데이터, 제주 평균 전력 사용량 데이터 등을 수집해 시계열 분석을 진행하였다.
본격적인 분석에 들어가기 앞서 종속변수인 풍력 발전량과 태양열 발전량과 깊은 상관관계가 있는 독립변수만 선정하여 모델링할 최종 데이터셋에 포함하고자 했는데, 이때 상관분석을 진행하였다.
상관분석 방법은 여러가지가 있는데,
1. pandas를 사용한 상관분석
pandas 라이브러리의 corr 메서드를 사용하면 데이터프레임의 상관계수를 쉽게 계산할 수 있다.
df = pd.DataFrame(data)
# 상관계수 계산
correlation_matrix = df.corr()
print(correlation_matrix)
2. Scipy를 사용한 상관분석
scipy 라이브러리의 pearsonr 메서드를 사용하여 피어슨 상관계수를 계산할 수 있다.
# 피어슨 상관계수 계산
pearson_corr, _ = pearsonr(x, y)
print(f'Pearson correlation: {pearson_corr}')
이번 실습에서는 2번 방법을 사용하였다.
2022~2023년의 날짜별 총 730개 행 전처리 데이터를 바탕으로 발전량(=공급량)을 예측하는 모델링을 진행하기 위해 독립변수 - 종속변수 간 상관관계 분석을 우선적으로 진행하여, 중요 피처만 선정하는 과정을 거쳤다.
(1) 기상데이터-태양광발전량 간의 상관관계
# 데이터 전처리
sun = pd.read_csv('sun.csv')
weather = pd.read_csv('weather.csv')
df = pd.merge(weather, sun, on='날짜')
# 상관분석할 피처 선정
solar_columns = ['교래태양광', '종합경기장 태양광', '행원태양광', '홍보관주차장 태양광', '수산태양광']
df = df.drop(columns=solar_columns + ['지점', '지점명'])
correlations = {}
p_values = {}
# 상관분석 진행
for column in df.columns:
if column not in ['태양광전체', '날짜', '교래태양광', '종합경기장 태양광', '행원태양광', '홍보관주차장 태양광', '수산태양광']:
# NaN 값 제거
valid_data = df[[column, '태양광전체']].dropna()
if len(valid_data) > 0:
corr, p_val = pearsonr(valid_data[column], valid_data['태양광전체'])
correlations[column] = corr
p_values[column] = p_val
results = pd.DataFrame({
'Correlation': correlations,
'P-Value': p_values
})
results = results[(results['P-Value'] <= 0.05)]
significant_results = results[(results['Correlation'].abs() >= 0.5)]
# 히트맵으로 상관분석 결과 시각화
plt.figure(figsize=(12, 10))
sns.heatmap(results, annot=True, fmt=".2f", cmap='coolwarm', center=0)
plt.title('변수 간 상관계수')
plt.show()
significant_results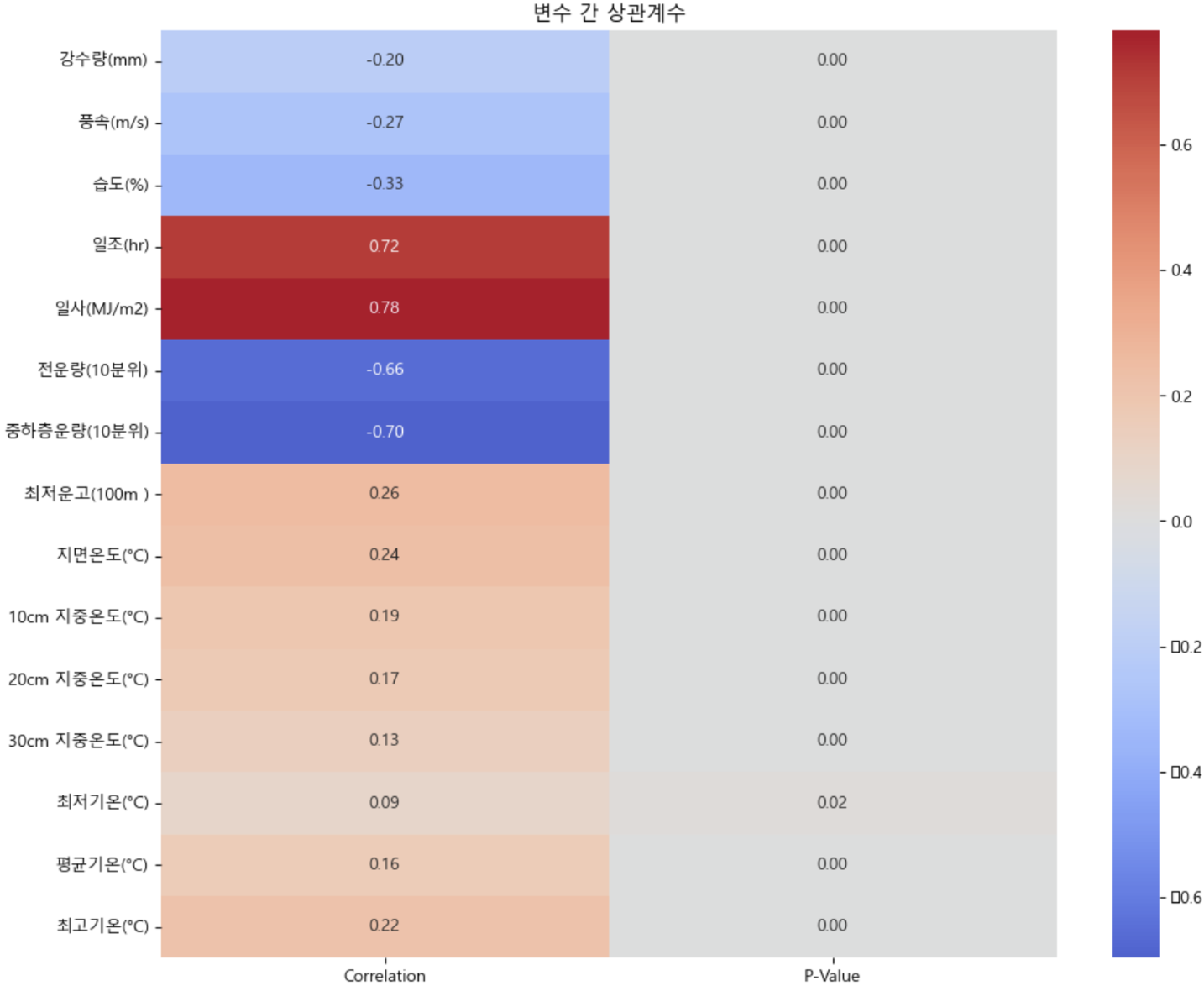
위와 같은 결과에서 상관계수 절대값이 0.5 이상이면서 p-value가 유의미한 독립변수만 채택하였다. 그 결과 일조, 일사, 전운량, 중하층운량이 태양광 발전량과 깊은 상관관계가 있음을 확인하고 모델링에 포함될 독립변수로 선정하였다.
(2) 기상데이터-풍력발전량 간의 상관관계
# 데이터 전처리
wind = pd.read_csv('풍력발전량.csv')
weather = pd.read_csv('기상데이터.csv')
wind['일시'] = pd.to_datetime(wind['일시']).dt.date
weather['날짜'] = pd.to_datetime(weather['날짜']).dt.date
df = pd.merge(weather, wind, left_on='날짜', right_on='일시')
df = df.drop(columns=['일시'])
wind_columns = ['가시리풍력', '김녕풍력','동복풍력','신창풍력','행원풍력']
df = df.drop(columns=wind_columns + ['지점', '지점명'])
# 상관분석 진행
correlations = {}
p_values = {}
# 상관계수 및 p-value 계산
for column in df.columns:
if column not in ['날짜', '풍력전체']:
# NaN 값 제거
valid_data = df[[column, '풍력전체']].dropna()
if len(valid_data) > 1: # 상관계수 계산을 위해 최소 2개 이상의 데이터 필요
corr, p_val = pearsonr(valid_data[column], valid_data['풍력전체'])
correlations[column] = corr
p_values[column] = p_val
results = pd.DataFrame({
'Correlation': correlations,
'P-Value': p_values
})
# 상관계수와 p-value를 데이터프레임으로 변환
corr_df = pd.DataFrame.from_dict(correlations, orient='index', columns=['Correlation'])
pval_df = pd.DataFrame.from_dict(p_values, orient='index', columns=['p-value'])
# 히트맵 시각화
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.heatmap(corr_df, annot=True, cmap='coolwarm', center=0, cbar_kws={'label': 'Correlation'})
plt.title('Correlation Heatmap')
plt.subplot(1, 2, 2)
sns.heatmap(pval_df, annot=True, cmap='viridis', cbar_kws={'label': 'p-value'}, norm=plt.Normalize(0, 0.05))
plt.title('p-value Heatmap')
plt.tight_layout()
plt.show()
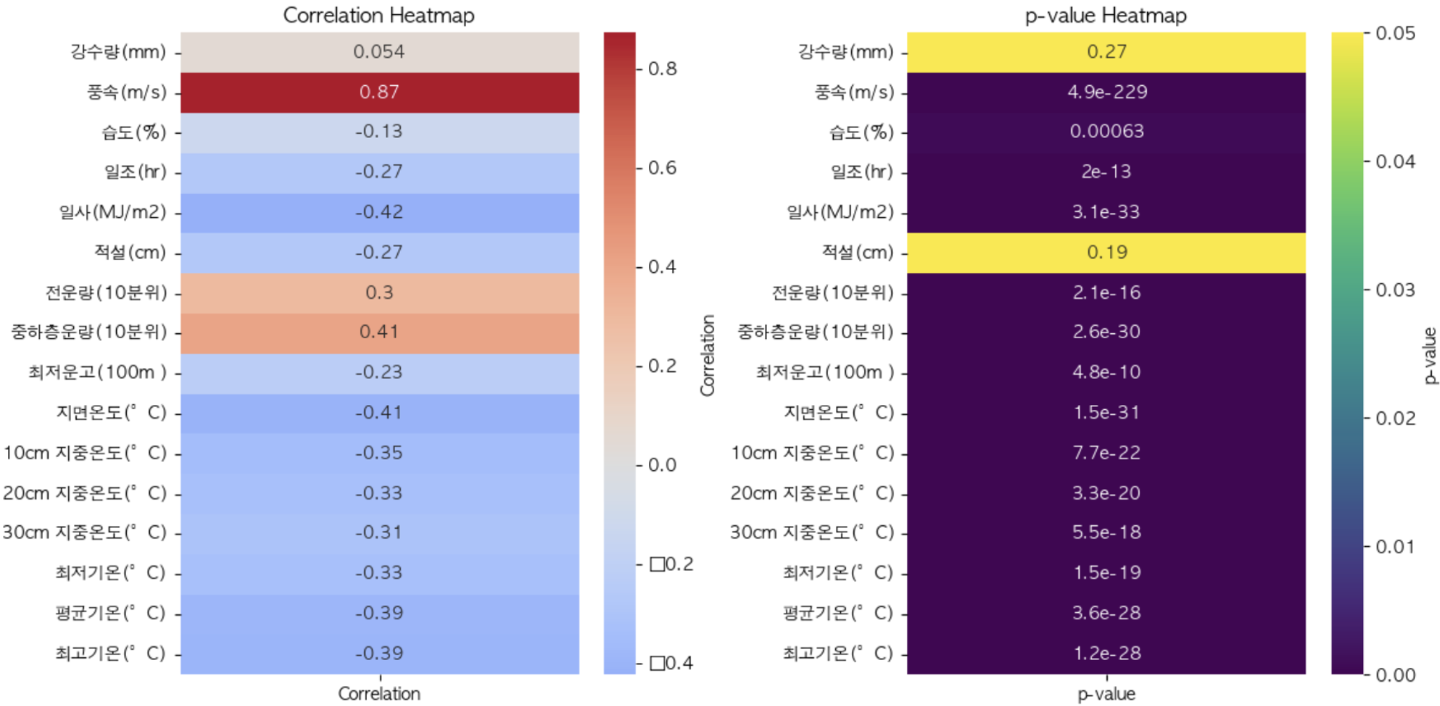
results = results[(results['P-Value'] <= 0.05)]
significant_results = results[(results['Correlation'].abs() >= 0.4)]
significant_results
위와 같은 결과에서 상관계수 절대값이 0.4 이상이면서 p-value가 유의미한 독립변수만 채택하였다. 그 결과 풍속, 일사, 중하층운량, 지면온도가 풍력 발전량과 깊은 상관관계가 있음을 확인하고 모델링에 포함될 독립변수로 선정하였다.
다.
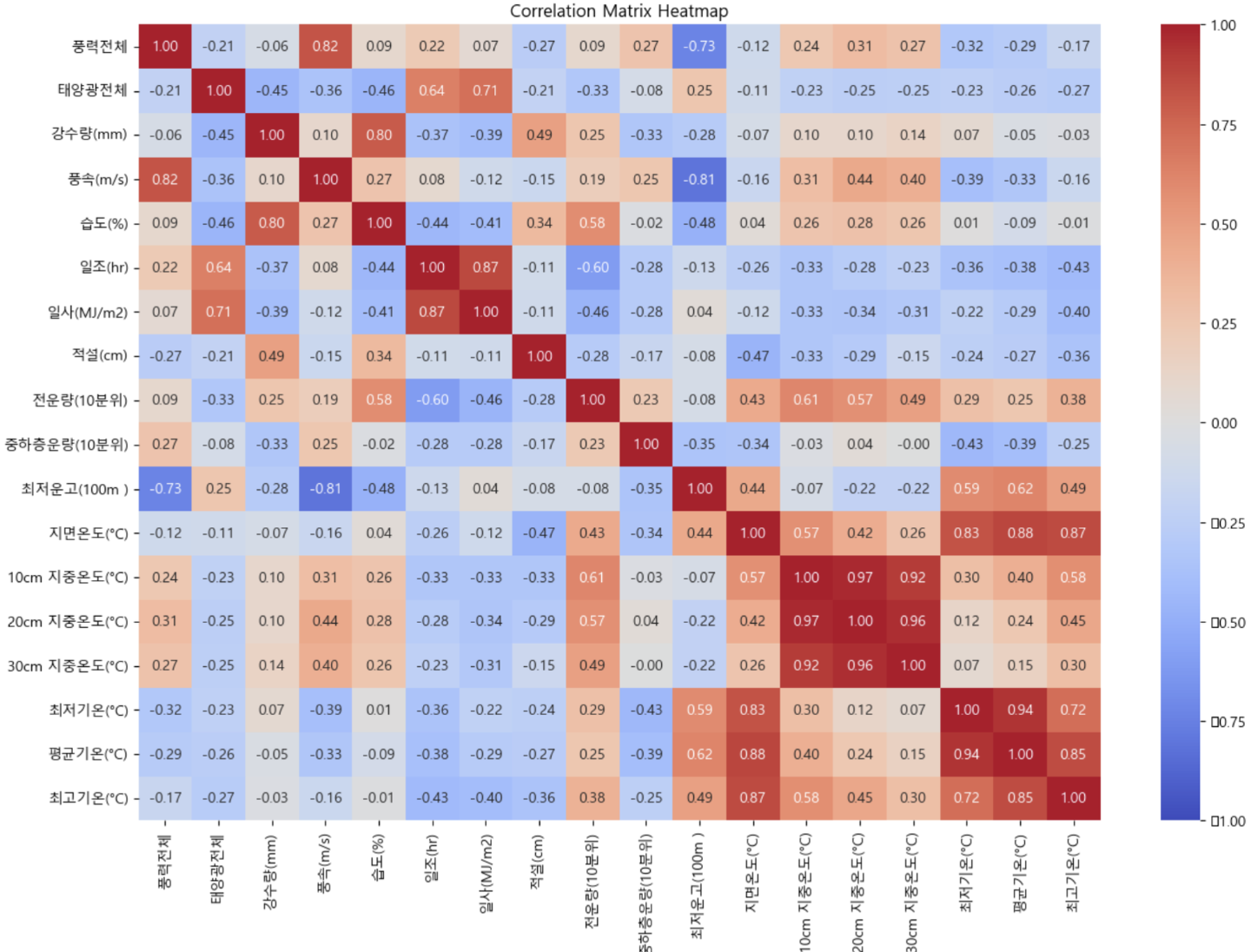
추가로 히트맵 시각화 결과 일부분에서 독립변수 간 강한 상관관계로 다중공선성 문제가 발생하지만, 본 연구가 모델로 사용할 시계열분석과 딥러닝 모델에는 영향을 미치지 않기에 별도로 고려하진 않았다.
'Data > Python' 카테고리의 다른 글
| [Python] 콘텐츠 기반 추천 시스템 (2) | 2024.12.13 |
|---|---|
| [Python] Featuretools로 고객데이터 분석하기 (0) | 2024.10.28 |
| [Python] 네이버 뉴스기사 크롤링하고 감성분석하기 (1) | 2024.06.25 |
| [Python] 데이터에서의 Outlier 처리 (1) | 2024.04.22 |
| [Python] selenium으로 워크넷 동적 크롤링하기 (0) | 2024.04.15 |



