

짜리몽땅 매거진
[Python] 네이버 뉴스기사 크롤링하고 감성분석하기 본문
금산인삼축제와 금산천벚꽃축제에 대한 전반적인 여론과 인식을 파악하고자 해당 축제명을 네이버에 검색했을 때 뜨는 뉴스기사 리스트를 크롤링한 후 크롤링한 기사의 제목을 네이버 CLOVA Sentiment API를 활용해 감성분석해보자.
먼저 네이버 뉴스기사를 크롤링해보자.
1. 라이브러리 호출
import pandas as pd
import numpy as np
import time
import re
from bs4 import BeautifulSoup
from datetime import datetime
from tqdm import tqdm
import requests
path = "/Users/your name/Desktop/"
2. 검색 키워드 및 개수 설정
# 필요한 키워드 입력
search_content = input("검색할 키워드를 입력해주세요: ")
max_news = int(input("\n몇 개의 뉴스를 크롤링할지 입력해주세요. ex) 1000(숫자만입력): "))
3. 검색 기간 설정
# 크롤링할 기간 설정
# ex) 2023년 금산인삼축제 기간: 2023.10.03 ~ 2023.10.13
# 따라서 축제 시작 전 3개월간의 뉴스를 크롤링
startday = ["2023.07.14"]
endday = ["2023.10.13"]
4. 크롤링, 파싱
# URL crawling 함수
# Redirect 되지않는 네이버뉴스 max_news개가 추출될때까지 크롤링을 계속하는 함수
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/98.0.4758.102"}
def url_crawling(search_content, start_season, end_season, max_news):
# 집합 형태로 저장해 중복 url 제거
url_set = set()
for start_day, end_day in zip(start_season, end_season):
for page in tqdm(range(1, 2000, 10)):
response = requests.get(f"https://search.naver.com/search.naver?where=news&sm=tab_pge&query={search_content}&start={page}&pd=3&ds={start_day}&de={end_day}", headers=headers)
# page를 넘기다 page가 없으면 종료
# 200은 HTTP 상태코드중 하나로 OK의 의미를 가짐. 요청이 성공적으로 처리되었음을 나타냄. 200이 아니라는것은 페이지가 없어 페이지를 넘길 수 없다는 의미
if response.status_code != 200:
print(f"페이지 {page//10}가 없습니다. Exiting.")
break
html = response.text
soup = BeautifulSoup(html, 'html.parser')
ul = soup.select_one("div.group_news > ul.list_news")
if ul is None:
break
li_list = ul.find_all('li')
for li in li_list:
a_list = li.select('div.news_area > div.news_info > div.info_group > a.info')
for a_tag in a_list:
href = a_tag.get('href')
# href 속성값이 "n.news.naver.com"(네이버 뉴스)을 포함하는지 확인한다.
if "n.news.naver.com" in href:
try:
# request.head()로 추출한 url이 rediret되는지 확인한다. redirect 되지않은 url만 저장한다.
response = requests.head(href, allow_redirects=True)
if response.status_code == 200:
url_set.add(href)
# 원하는 개수의 기사가 모두 크롤링 되었으면 크롤링 종료
if len(url_set) >= max_news:
return list(url_set)
except Exception as e:
print(f"An error occurred: {e}")
time.sleep(1)
return list(url_set)
url = url_crawling(search_content, startday, endday, max_news)
len(url)
5. 필요 내용 추출, 리스트 담기
news_url = url
# 신문사, 제목, 본문 추출
news_company = []
news_title = []
news_content = []
for url in tqdm(news_url):
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
company = soup.select_one("#ct > div.media_end_head.go_trans > div.media_end_head_top > a > img[alt]")
news_company.append(company['alt'] if company else 'None')
title = soup.select_one("#ct > div.media_end_head.go_trans > div.media_end_head_title > h2")
news_title.append(title.text if title else 'None')
content = soup.select_one("article#dic_area")
news_content.append(content.text if content else 'None')
# 데이터프레임 생성
columns = ["company", "url", "title", "content"]
data = {
"company": news_company,
"url": news_url,
"title": news_title,
"content": news_content
}
df_news = pd.DataFrame(data, columns=columns)
df_news.head()

이제 크롤링을 완료했으니 해당 뉴스기사의 제목을 감성분석해 축제에 대한 인식을 확인해보자.
1. 라이브러리 호출
import pandas as pd
import requests
import json
path = "/Users/your name/Desktop/"
2. 감성분석 api 호출 및 함수 정의
import requests
import json
import pandas as pd
def Sentiment_API(df, column_name):
client_id = '' # 마스킹
client_secret = '' # 마스킹
url = "https://naveropenapi.apigw.ntruss.com/sentiment-analysis/v1/analyze"
headers = {
"X-NCP-APIGW-API-KEY-ID": client_id,
"X-NCP-APIGW-API-KEY": client_secret,
"Content-Type": "application/json"
}
sentiments = []
for content in df[column_name]:
# 950글자까지로 지정
# API가 1000까지만 처리됨
data = {
"content": content[:950]
}
response = requests.post(url, data=json.dumps(data), headers=headers)
result = json.loads(response.text)
highlights = []
for sentence in result["sentences"]:
highlights.append(sentence.get("highlights", []))
sentiments.append({
"label": result["document"]["sentiment"],
"confidence": result["document"]["confidence"],
"highlights": highlights
})
sentiments_df = pd.DataFrame(sentiments)
df = pd.concat([df, sentiments_df], axis=1)
return df
def extract_highlighted_text(df, title_column, highlights_column):
highlighted_texts = []
for idx, row in df.iterrows():
title = row[title_column]
highlights = row[highlights_column]
extracted_texts = []
for highlight_set in highlights:
for highlight in highlight_set:
offset = highlight['offset']
length = highlight['length']
extracted_texts.append(title[offset:offset + length])
highlighted_texts.append(' '.join(extracted_texts))
df['highlighted_texts'] = highlighted_texts
return df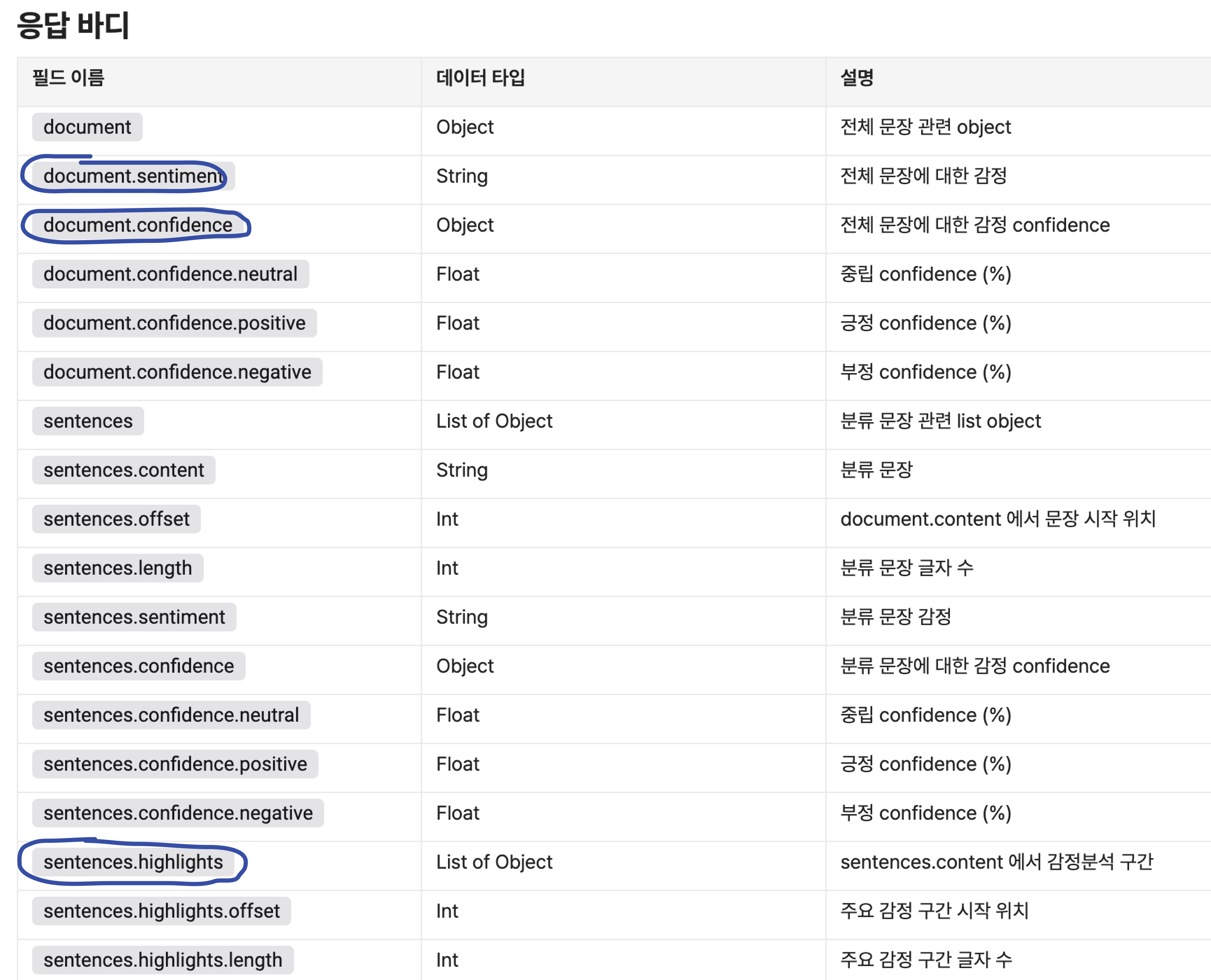
네이버 CLOVA Sentiment API에서 제공하는 여러 정보 중에 감성 라벨, 신뢰도, 주요 감정 구간만을 출력한다.
3. 감성분석하기
# 감성분석 데이터셋
df = pd.read_excel("금산인삼축제 뉴스기사 크롤링.xlsx")
df_sentiment = Sentiment_API(df, 'title')
df_with_highlights = extract_highlighted_text(df_sentiment, 'title', 'highlights')
df_sentiment
4. 감성분석 기여단어 추출(TF-IDF vectorizer 활용)
import pandas as pd
from konlpy.tag import Okt
from sklearn.feature_extraction.text import TfidfVectorizer
# 형태소 분석기 초기화
okt = Okt()
# highlighted_texts 컬럼을 형태소 단위로 나누기
df_sentiment['tokenized_highlighted_texts'] = df_sentiment['highlighted_texts'].apply(lambda x: ' '.join(okt.nouns(x)))
# TF-IDF 벡터라이저 초기화
vectorizer = TfidfVectorizer()
# TF-IDF 행렬 생성
tfidf_matrix = vectorizer.fit_transform(df_sentiment['tokenized_highlighted_texts'])
# 단어 리스트 추출
terms = vectorizer.get_feature_names_out()
# 제목별로 중요한 단어 1개 추출
def extract_top_word(row):
tfidf_vector = tfidf_matrix[row.name].toarray().flatten()
top_index = tfidf_vector.argmax()
top_word = terms[top_index]
return top_word
# 각 제목별로 중요한 단어 1개 추출하여 'top_word' 컬럼에 저장
df_sentiment['top_word'] = df_sentiment.apply(extract_top_word, axis=1)
# 필요한 컬럼만 선택하여 최종 데이터프레임 생성
df_final = df_sentiment[['highlighted_texts', 'top_word', 'label', 'confidence']]
# 최종 데이터프레임 출력
print(df_final)
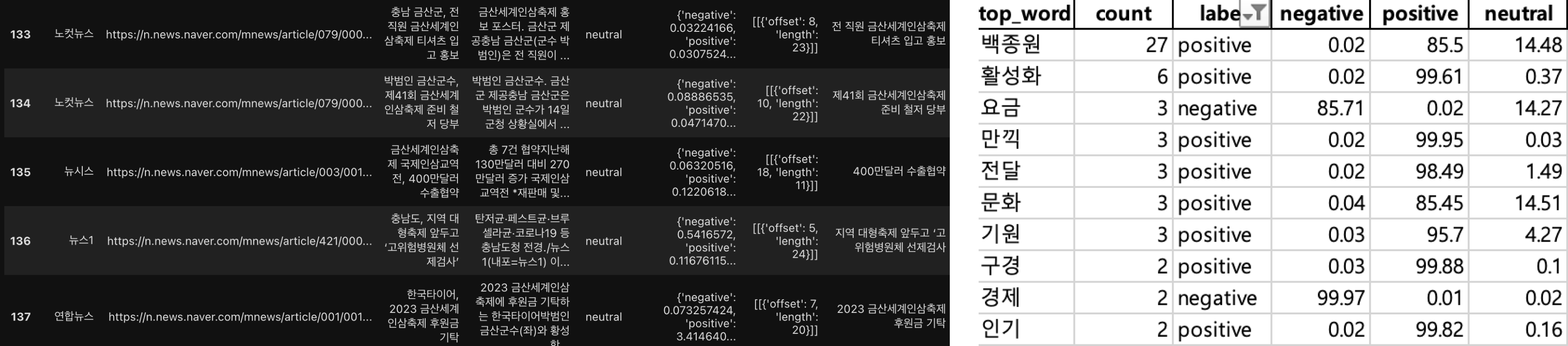
KoNLPy Okt를 활용한 형태소 분석을 진행한 후 TF-IDF 벡터화를 통해 제목별 주요 감정 구간에서 감성분석 결과 최고 기여한 단어를 추출한다.
감성 분석(Sentiment Analysis)은 텍스트 데이터를 분석하여 그 속에 담긴 감정이나 감정을 파악하는 자연어 처리(NLP)의 한 분야이다. 크롤링한 뉴스기사 제목은 핵심적인 정보를 담고 있으며, 해당 기사에서 전달하고자 하는 주요 감정을 반영한다고 판단했기에 기사 제목 데이터를 감성분석에 활용했다. 해당 실습에서는 타겟 축제인 ‘금산인삼축제'와 ‘금산천벚꽃축제'에 대한 긍정, 부정, 중립적인 감정을 뉴스기사 제목을 바탕으로 분석해, 축제에 대한 전반적인 여론과 인식을 파악할 수 있었다.
'Data > Python' 카테고리의 다른 글
| [Python] 상관분석 (0) | 2024.07.01 |
|---|---|
| [Python] 데이터에서의 Outlier 처리 (0) | 2024.04.22 |
| [Python] selenium으로 워크넷 동적 크롤링하기 (0) | 2024.04.15 |
| [Python] beautifulsoap으로 당근마켓 정적 크롤링하기 (0) | 2024.04.14 |
| [Python] 데이터에서의 Missing Value 처리 (0) | 2024.03.29 |


